Cloud App Architecture
This notes is taken from Microsoft Azure Architecture Center. These principles still apply to any cloud applications not just limited to Azure.
Architecture styles¶
An architecture style is a family of architectures that share certain characteristics.
An architecture style places constraints on the design, including the set of elements that can appear and the allowed relationships between those elements.
Before choosing an architecture style, make sure that you understand the underlying principles and constraints of that style. Otherwise, you can end up with a design that conforms to the style at a superficial level, but does not achieve the full potential of that style. It's also important to be pragmatic. Sometimes it's better to relax a constraint, rather than insist on architectural purity.
Weigh the tradeoffs¶
Constraints also create challenges, so it's important to understand the trade-offs when adopting any of these styles.
Some main challenges to consider:
- Complexity - is the style too simplistic or too complex for your domain? Is it managable?
- Asynchronous messaging and eventual consistency - is eventual consistency guaranteed? Any possiblity for lost message or duplicated messages?
- Inter-service communication - how much overall latency will be increased from the separated components? Will there be network ingestion?
- Manageability - how hard to monitor, deploy, extend the app?
Common Styles¶
N-tier¶

N-tier - a traditional architecture for enterprise apps, where dependencies are managed by dividing the application into layers that perform logical functions, such as presentation, business logic, and data access.
Layers is a way to separate responsibilities and manage dependencies. A layer can only call into layers that sit below it, which makes it hard to introduce changes in one part of the application without touching the rest of the application.
Tiers are physically separated, running on separate machines. A tier can call to another tier directly, or use asynchronous messaging (message queue). Several layers might be hosted on the same tier.
Physically separating the tiers improves scalability and resiliency, but also adds latency.
N-tier is most often seen in infrastructure as a service (IaaS) solutions.
An N-tier application can have a closed layer architecture (a layer can only call the next layer immediately down) or an open layer architecture (a layer can call any of the layers below it).
Benefits:
- portabilityp
- simplicity in design
Challenges:
- largely monolithic design prevents independent deployment of features
Best practices:
- avoid a middle layer that only does CRUD operations to data tier which adds latency
- use autoscaling to handle load changes
- use asynchronous messaging to decouple tiers
- cache semistatic data
- make database tier highly available
- place Web Application Firewall (WAF) between frontend and the Internet to block abuse
- place each tier in its subnet and use subnets as a security boundary
- restrict data tier to only middle tier
Web-Queue-Worker¶

A Web-Queue-Worker app has a web frontend that handles HTTP requests and a backend worker that performs CPU-intensive tasks or long-running operations. The front end communicates to the worker through an asynchronous message queue.
Other components that can be commonly incorporated:
- database
- cache
- CDN
- remote service
- identity provider for authentication
The web frontend and worker should be stateless. Session state can be stored in a distributed cache. Any long-running or resource-intensive work is done by the worker asynchronously through active poll or periodical batch-processing, otherwise the worker is optional.
The frontend and the worker can easily become large, monolithic components, and involves complex dependencies, which makes it hard to maintain and update.
Benefits:
- simplicity in design, deploy, and manage
- separation of concerns
- good scalability for the decoupled componets
Challenges:
- components can still get large and monolithic, making it hard to maintain and update
- hidden dependencies in terms of data schemas or modules for communication
Best practices:
- expose a well-designed API to client
- use autoscaling to handle load changes
- cache semistatic data
- use a CDN to host static content
- partition data to improve scalability, reduce contention, and optimize performance
Microservices¶

A microservice app is composed of many small, independent services. Each service implements a single business capability. Services are loosely coupled, communicating through API contracts.
Each service can be built by a small, focused development team. Individual services can be deployed without a lot of coordination between teams, which encourages frequent updates. Services are responsible for persisting their own data or external state.
However, this architecture is more complex to build and manage and requires a mature development and DevOps culture. Done right, this style can lead to higher release velocity, faster innovation, and a more resilient architecture.
Management/orchestration component is responsible for placing services on nodes, identifying failures, and rebalancing services across nodes. For example, Kubernetes, and certain public cloud services.
API Gateway - the entry point for clients which forwards the call to the appropriate services on the back end.
Benefits:
- Agile development
- Small, focused teams for each service
- Small code base on each service
- Mix of technologies, some services can be built with different stacks
- Fault isolation, some services failure will not bring down the whole service
- Better scalability, independent scaling
- Data isolation, each service owns its data. But common schema changes are tricky.
Challenges:
- Complexity, more moving parts and need to make sure they work in harmony
- Development and testing, hard to test service dependencies
- Lack of goverance, may end up with things built with different stacks and styles and making it harder to maintain and see the entire picture
- Network ingestion and latency, more components lead to more inter-service communication. Reduce unnecessary calls, use more efficient serialization formats, and switch to asynchronous communication patterns helps
- Data integrity, data consistency can become a problem as each service keeps its own state
- Management, logging and tracing, DevOps
- Versioning, potential backward or forward compatibility
- Skill set for building highly distributed systems
Best practices:
- Decentralize as much as possible
- API should be designed around the business domain
- offload auth and SSL termination to the Gateway
- The gateway should handle and route client requests without any knowledge of the business rules or domain logic
Event-driven¶

An application of event-driven architecture use a publish-subscribe (pub-sub) model, where producers publish events, and consumers subscribe to them. The producers are independent from the consumers, and consumers are independent from each other.
Events are delivered in near real time, so consumers can respond immediately to events as they occur, and every consumer sees all of the events.
This architecture is good for apps that ingest and process large volume of data with low latency, or when multiple different subsystems must perform different types of processing on the same event data. Two Event-driven architecture variations:
- The Pub/Sub model - sends published events to each subscriber and the events cannot be replayed and new subscribers do not see past events.
- The Event streaming model - writes events to a log and keeps the events strictly ordered and persistent. Consumers can read from any part of the stream and is responsible for advancing its position in the stream. A consumer can join any time and replay past events.
Three common consumer variations:
- Simple event processing, each event immediately triggers an action
- complex event processing, the consumer processes a series of events to look for a pattern, like aggregation over sliding time windows
- event stream processing, use a pipeline to ingest events and to process or transform the stream. Good for IoT workloads.
Benefits:
- decoupled design of producers and consumers
- easy to add or remove consumers
- consumers respond to events immediately
- highly scalable and distributed
- consumers can have independent view of the event stream
Challenges:
- Guaranteed delivery is essential
- Process events in order or exactly once can be hard to guarantee
Best practices:
- keep events as small as possible
- services should really only share IDs and maybe a timestamp to indicate when the information was effective
- think about which service should own which piece of data, and avoid sharing those pieces in a single giant event.
Another great read about Event-driven design https://particular.net/blog/putting-your-events-on-a-diet and RPC's disadvantage against messaging or event-driven design https://particular.net/blog/rpc-vs-messaging-which-is-faster
Big Data¶
Big data and Big Compute are specialized architecture for workloads that fit certain specific profiles.

Big data divides a very large dataset into chunks, performing parallel processing across the entire set, for analysis and reporting.
It usually involves:
- Batch processing of big data stored
- app data in relational DB, static files, logs
- source data stored in Data Lake, typically distributed storage, high volumes, various formats, include blobs (Binary Large Object)
- Map/Reduce are often used
- repeated processing operations encapsulated in workflows
- Real-time processing of big data in motion
- IoT event data
- events typically are compressed and serialized into binary format
- a message ingestion store to act as a buffer for messages is needed
- support scale-out processing, reliable delivery, message queuing
- Interactive exploration of big data
- Predictive analytics and machine learning
- data modeling layer
Benefits:
- Parallelism
- Elastic scale, scale up both borizontally and vertically on the components as needed
- Interoperability and extensibility, new workload can integrate into existing solutions
Challenges:
- Complex to build and configure for each system in the picture
- Skillset is specialized, many frameworks and languages are not used in general application architectures
- Evolving technology, some are still evolving fast and introduce big changes across releases
- Security, properly govering data access
Best practices:
- partition the data to reduce ingestion
- apply schema-on-read semantics, which project a schema onto the data when the data is processing, not when the data is stored. It is less likely to cause slow downs from bottlenecks such as validation and type checking.
- adjust the parallelism for the best balance in utilization costs and time
- scrub sensitive data early in the data pipeline
Big Compute¶
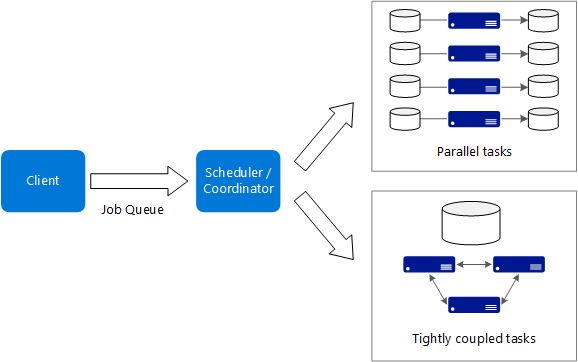
Big compute, aka high-performance computing (HPC), makes parallel computations across a large number (thousands) of cores, mostly used on simulations, modeling, rendering, or any jobs that requires too much memory to fit on single machine.
The work must be able to split into discrete tasks, and each task is finite. The application can be spun up ad-hoc.
For tightly coupled tasks, high-speed networking is required for exchanging intermediate results fast.
Challenges:
- Manage VM infrastructure
- Provision thousands of cores timely
- Experiment to find optimum number of cores, parallelism, and cost
Design Principles¶
Design for self-healing¶
A three-pronged approach:
- Detect failures
- Respond to failures gracefully
- Log and monitor failures to give operational insight
Recommendations:
- Retry failed operations for transient failures
- Protect failing remote services via circuit breaker for persistent failures to prevent overwhelming retries causing cascading failures
- Isolate critical resources, partition a system into isolated groups, so that a failure in one partition does not bring down the entire system
- Perform load leveling, use a queue-based load leveling pattern to queue work items to run asynchronously and prevent sudden spikes take down the entire system
- Fail over to backup region or cluster. For stateless services, put instances behind a load balancer. For stateful services, use replicas for fail over (and handle eventual consistentcy).
- Compensate failed transactions, compose an operation from smaller individual transactions. Rewind back if the operation fails midway through.
- Checkpoint long-running transactions, allow the operation resume from last checkpoint in event of a failure.
- Degrade gracefully, provide reduced functionality when the primary function is broken.
- Throttle bad clients, throttle clients making excessive load abusively
- Block bad actors, define out-of-band process to detect bad clients and block their access for some period of time
- Leader election on coordinators to avoid single-point-failure
- Perform fault injection tests, test the resiliency of the system responding possible failure-scenarios either by triggering actual failures or simulate them
- Chaos engineering by randomly injecting failure conditions into production instances
Build redundancy into application¶
Identify the critical paths in your application. Is there redundancy at each point in the path? When a subsystem fails, will the application fail over to something else?
Recommendations:
- Weigh the cost increase, the complexity, and operational procedures introduced from the amount of redundancy built into a system and decided if it justify the business scenario
- Put multiple VMs behind the load balancer.
- Replicate databases across regions to have quick fail over. Document fail over procedures or implement the observability layer to do so promptly
- Partition for availability. If one shard goes down, the other shards can still be reached.
- Deploy to multiple regions for higher availability.
- Synchronize frontend, backend, and database failover. Depending on the system, the backup region may require the whole stack to be failover to function properly.
- Use automatic failover but manual failback. Involve engineers to verify that all application subsystems are healthy before manually failing back. Also check dta consistency before failing back.
- Redundancy for Traffic Manager, as it is a possible failure point.
Minimize coordination¶
Most cloud apps runs multiple instances for scalability and reliability. When several instances try to perform concurrent operations that affect a shared state, there must be coordination across these instances.
Coordination through locks creates performance bottlenecks, and as more instances are scaled up, the lock contention increases. A better approach is to partition the work space from number of workers, each worker only affects its assigned portion.
Recommendataions:
- Embrace eventual consistency. The Compensating Transaction pattern can be used to incrementally apply transactions and roll back everything when necessary.
- Use domain events to synchronize state. Domain event is an event that has significance within the domain. Interested services can listen for the event and act accordingly, rather than relying on coordination.
- Partition data into shards
- Design idempotent operations so they can be handled with at-least-once semantics and making it easy to retry upon failures and crashes
- Use optimistic concurrency when possible. Pessimistic concurrency control uses database locks to prevent conflicts. Optimistic concurrency let each transaction modifies a copy or snapshot of the data, and have database engine validate the committed transaction and rejects others that breaks database consistency.
Design to scale¶
Design your application so that it can scale horizontally and quickly, adding or removing new instances as demand requires.
Recommendations:
- Avoid instance stickiness/affinity, or when requests from the same client are always routed to the same server. Traffic from a high-volume user will not be distributed across instances.
- Identify bottlenecks and resolve them first before scaling up. Stateful parts of the system are the most likely cause of bottlenecks.
- Offload resource-intensive tasks as offline jobs or asynchronously handled workloads if possible, to easy the laod on the frontend.
- Graceful scale down, instances being removed should handle the termination gracefully and clean up its states.
- listen for shutdown events
- clients should support transient fault handling and retries, in the event its remote origin gets terminated
- set breaking points for long-running tasks to be stopped and resumed
- put work items on a queue so another instance can pick up the work
Partition around limits¶
In the cloud services have limits in their ability to scale up, such as number of cores, memory available, database size, query throughput, and network throughput. Use partition to work around these limits.
- partition a database to avoid limits on database size, data I/O, number of concurrent sessions.
- partition a queue or message bus to avoid limits on number of requests or the number of concurrent connections.
- partition an App Service web app to avoid limits on the number of instances per App Service plan.
A database partition can be:
- horizontally - aka sharding, each partition holds data for a subset of the total data set. The partitions share the same data schema.
- vertically - each partition holds a subset of the fields for the items in the data store
- functionally - data is partitioned according to how it is used by each bounded context in the system, and the schemas are independent.
Recommendataions:
- Besides database, consider also partition storage, cache, queues, and compute instances
- Design the partition key to avoid hotspots. Refer to consistent hashing, sharding
- When it is possible to partition at multiple layers, it is easier to partition lower layers first in the hierarchy.
Design operations tools¶
Some important operations functions for cloud applications:
- Deployment
- Logging and tracing
- Monitoring
- Escalation
- Incident response
- Security auditing
Recommendataions:
- Make all things observable. Logging captures individual events, app states, errors, exceptions. Tracing records a path through the system and is useful to pinpoint bottlenecks, performance issues, and failure points.
- Instrument for monitoring, it should be as close to real-time as possible to discover issues that breach SLA
- Instrument for root cause analysis
- Use distributed tracing. Traces should include a correlation ID that flows across service boundaries
- Standardize logs and metrics. Define a common schema that can be derived to add custom fields, but all logs should be capable for tracing and aggregation.
- Treat configuration as code. Check configuration files into a version control system.
Use managed services¶
IaaS is like having a box of parts. You can build anything, but you have to assemble it yourself. PaaS options are easier to configure and administer. You are delegating some operational responsibility to a more focused team that manages it for everyone else.
Use suitable data store¶
In any large solution, it's likely that a single data store technology won't fill all your needs. Alternatives to relational databases include key/value stores, document databases, search engine databases, time series databases, column family databases, and graph databases.
Embrace polyglot persistence and put different types of data into the storage that best fit its type. For example, put transactional data into SQL, put JSON documents into a document database, put telemetry data into a time series data base, put application logs in Elasticsearch, and put blobs in HBase or other blob storage.
Recommendations:
- Prefer availability over (strong) consistency. Achieve higher availability by adopting an eventual consistency model.
- Consider the skillset of the development team. To adopt a new data storage technology, the development team must learn and understand appropriate usage patterns, how to optimize queries, tune for performance, and so on to get the most out of it.
- Use compsensating transactions to undo any completed steps in a failed transaction.
- Look at bounded contexts. A bounded context is an explicit boundary around a domain model, and defines which parts of the domain the model applies to. A bounded context maps to a subdomain of the business domain. The bounded contexts in your system are a natural place to consider polyglot persistence.
Design for evolution¶
All successful applications change over time, whether to fix bugs, add new features, bring in new technologies, replace existing components, or make existing systems more scalable and resilient.
Recommendations:
- Enforce high cohesion and loose coupling. If you find that updating a service requires coordinated updates to other services, it may be a sign that your services are not cohesive.
- a service is cohesive if it groups functionalities that logically belongs together
- loosely coupled services allows changing one without affect another
- Use asynchronous messaging, it is effective in creating loosely coupled systems
- Expose open interfaces. A service should expose an API with a well-defined API contract, and avoid creating custom translation layers that sit between services. The API should be versioned for maintaining backward compatibility. Public facing services should expose a RESTful API over HTTP. Backend services might use an RPC-style messaging protocol for performance reasons.
- Design and test against service contracts. When services expose well-defined APIs, you can develop and test against those APIs.
- Abstract infrastructure away from domain logic. Don't let domain logic get mixed up with infrastructure-related functionality, such as messaging or persistence.
- Offload shared functionality to a separate service, which allows it getting evloved independently.
- Deploy services independently. Updates can happen more quickly and safely.
Build for the business needs¶
Ultimately, every design decision must be justified by a business requirement. Do you anticipate millions of users, or a few thousand? Is a one-hour application outage acceptable? Do you expect large bursts in traffic or a predictable workload? so on
Recommendations:
- Define business objectives, including the recovery time objective (RTO), recovery point objective (RPO), and maximum tolerable outage (MTO). These numbers should inform decisions about the architecture.
- Document service level agreements (SLA) and service level objectives (SLO). It is a business decision to set these numbers to define how reliable the system must be built for.
- Model the application around the business domain. Analyzing the business requirements. Consider using a domain-driven design (DDD) approach to create domain models that reflect the business processes and use cases.
- Capture both functional and nonfunctional requirements. Functional requirements let you judge whether the application does the right thing. Nonfunctional requirements let you judge whether the application does those things well. Understand your requirements for scalability, availability, and latency
- Plan for growth. A solution might meet your current needs, in terms of number of users, volume of transactions, data storage, and so forth. A robust application can handle growth without major architectural changes.
- Manage costs. Traditional on-premises application pays upfront for hardware as a capital expense. In a cloud application, you pay for the resources that you consume so understand the pricing model for the services that you consume. Also consider your operations costs.