Some of the images references from this notes are referenced from geeksforgeeks.org and wikipedia.org .
Data Structures Implementation¶
These Data Structures are your friends:¶
- Array, Matrix, LinkedList, Double LinkedList
- Stack, Queue
- Binary Search Tree, Trie, Heap
- HashMap, HashSet
- Graph Adjacent List
Stack¶
Stack is a first-in-last-out data structure, good for hold state (temporarily) then process more recent elements.
Use Stack also to turn recursive logic into iterative, mostly in DFS, where the call stack can be large for recursion, i.e. processing parenthesis errors. Use it also to solve cases when it is necessary to (partially) revert the order of some data sets.
Stack is also useful for binary tree in-order traversal, as well as BST in-order traversal to find kth largest element.
Monotonous Stack¶
Monotonous Stack is not a new type of Stack, just that we force a property on top of its elements such that we only store elements coming in strict increasing or decreasing order; if a new element to be inserted breaks this rule, then we continue pop elements out until that property is maintained again.
With this property, a Monotonous Stack can use O(n) to find the immediate elements (on left and right side) that are smaller than a chosen element, for any elements in the list. It is good for identify and calculate base on the local min/max.
This type of property is especially useful for when need to calculate a sum/product of many continuous elements following an increasing or decreasing order.
Queue¶
Queue is a first-in-first-out data structure, often used in tree level-order traversal through BFS.
Trees¶
Tree is a data structure that each tree node may contain a value, and child nodes. Binary tree are the most used tree types. There are also n-ary tree like Trie.
Use divide conquer on binary tree problems to calculate from small units and merge back up to final result.
Binary Tree Divide Conquer
Recursion often used for traversing binary trees
public Result divideConquer() {
if (node == null) {
return ...;
}
Result left = divideConquer(node.left);
Result right = divideConquer(node.right);
Result result = merge(left, right);
return result;
}
BSTs¶
Binary Search Trees (BST) are also called ordered or sorted binary tree. It is a binary tree data structure where for each root node, stores a key greater than all the keys in the node’s left subtree and less than those in its right subtree.
BST allow fast binary search to lookup value, of O(log(n)). A BST's in-order expand the data into a sorted list.
Since for the worst case the number of nodes of a tree can be equal to the hight of the tree which cause lookups take linear time O(n), Balanced BSTs are often used.
Traverse BST
Use iteration with help of Stack to in-order traverse a BST:
public Result problem() {
List<Node> inorder = new ArrayList<>();
Stack<Node> stack = new Stack<>();
Node dummy = new Node();
dummy.right = root;
stack.push(dummy);
while (!stack.isEmpty()) {
Node curr = stack.pop(); // safe to assume curr's left subtree are processed at this point
if (curr.right != null) { // work on the right subtree
curr = curr.right;
while (curr != null) {
stack.push(curr);
curr = curr.left; // push left nodes all the way
}
}
if (!stack.isEmpty())
inorder.add(stack.peek()); // only take its value, it will be poped in next iteration
}
return inorder;
}
Red-Black Tree¶
A red-black tree is a kind of self-balancing binary search tree (BST) where each node has an extra bit, and that bit is often interpreted as the colour (red or black). These colours are used to ensure that the tree remains balanced during insertions and deletions.
Most of the BST operations (e.g., search, max, min, insert, delete.. etc) take O(h) time where h is the height of the BST. The cost of these operations may become O(n) for a skewed Binary tree. If we make sure that the height of the tree remains O(log n) after every insertion and deletion, then we can guarantee an upper bound of O(log n) for all these operations. The height of a Red-Black tree is always O(log n) where n is the number of nodes in the tree.
Rules That Every Red-Black Tree Follows:
- Every node has a colour either red or black.
- The root of the tree is always black.
- There are no two adjacent red nodes (A red node cannot have a red parent or red child).
- Every path from a node (including root) to any of its descendants NULL nodes has the same number of black nodes.
- All leaf nodes are black nodes.
The balance of Red-Black tree is not perfect, compare to AVL Tree. But it does fewer rotations during insertion and deletion. It is good for use cases where many more insertions/deletions occur to the tree. Otherwise use AVL Tree.
Red-Black Tree Properties:
- Black height of the red-black tree is the number of black nodes on a path from the root node to a leaf node. Leaf nodes are also counted as black nodes. So, a red-black tree of height h has
black height >= h/2. - Height of a red-black tree with n nodes is
h <= 2 log_2(n + 1). - All leaves (NIL) are black.
- The black depth of a node is defined as the number of black nodes from the root to that node i.e the number of black ancestors.
- Every red-black tree is a special case of a binary tree.
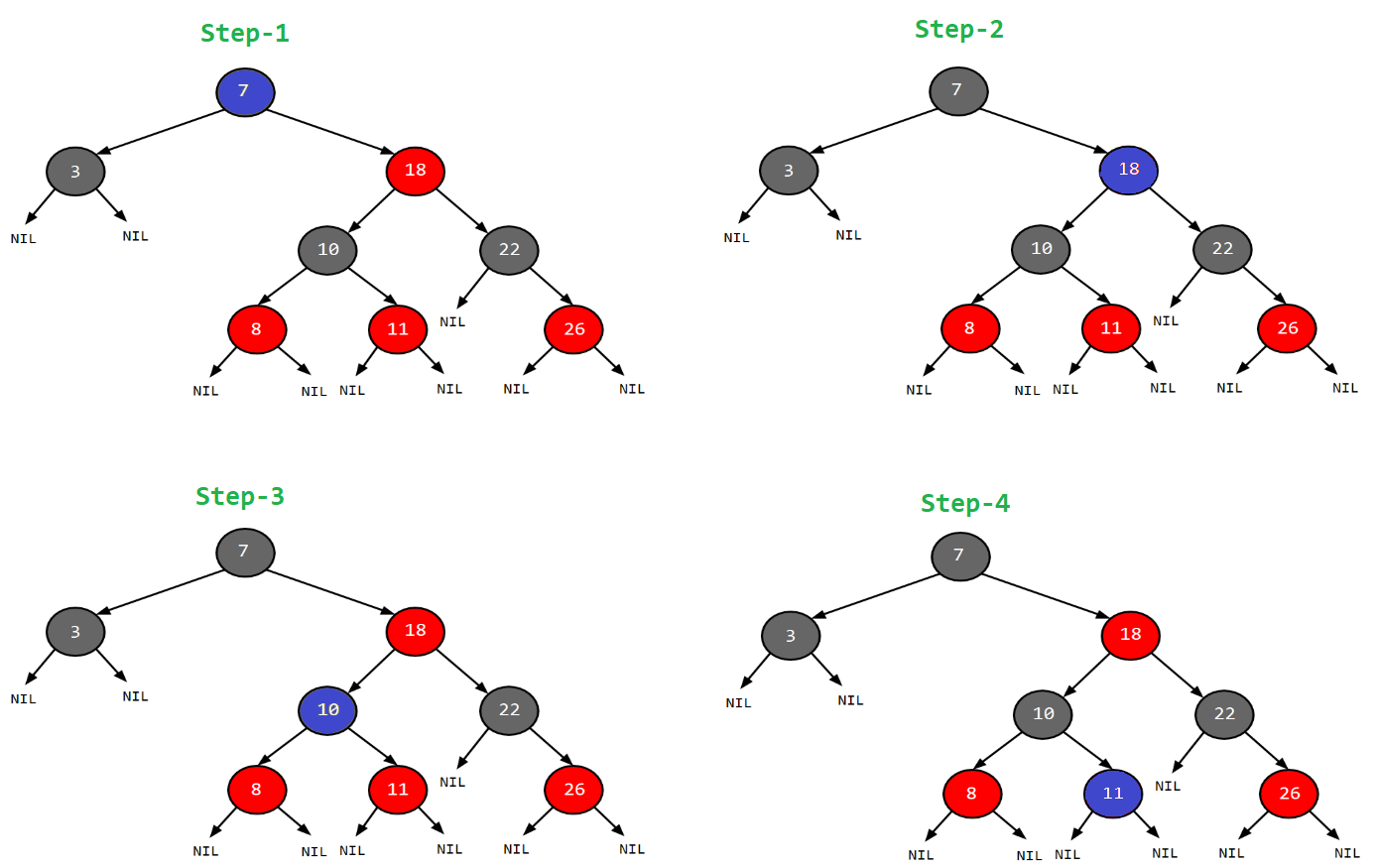
Let x be the newly inserted node.
- Perform standard BST insertion and make the colour of newly inserted nodes as RED.
- If x is the root, change the colour of x as BLACK (Black height of complete tree increases by 1).
- Do the following if the color of x’s parent is not BLACK and x is not the root.
- If x’s uncle is RED (Grandparent must have been black from property 4)
- Change the colour of parent and uncle as BLACK.
- Colour of a grandparent as RED.
- Change x = x’s grandparent, repeat steps 2 and 3 for new x.
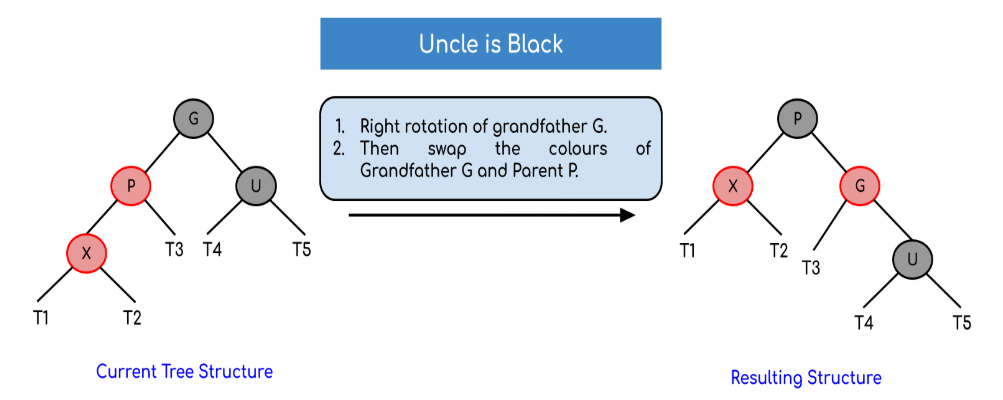
- If x’s uncle is BLACK, then there can be four configurations for x, x’s parent (p) and x’s grandparent (g) (This is similar to AVL Tree)
- If x’s uncle is RED (Grandparent must have been black from property 4)
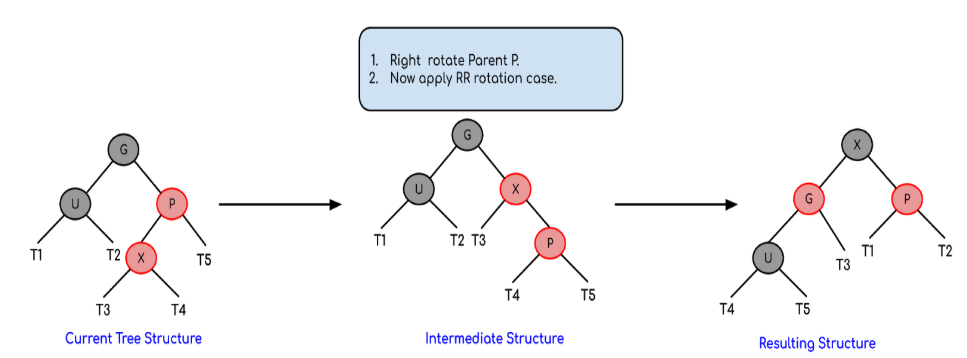
Left Left Case (p is left child of g and x is left child of p)
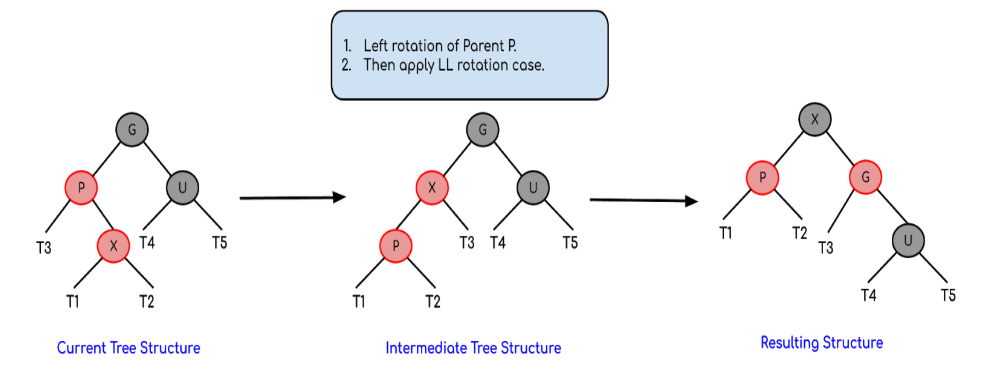
Left Right Case (p is left child of g and x is the right child of p)
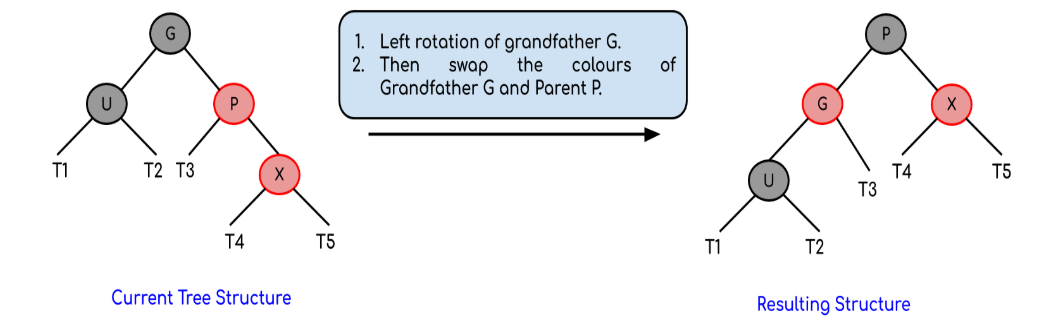
Right Right Case (Mirror of Left Left Case)
Right Left Case (Mirror of Left Right Case)
https://www.geeksforgeeks.org/red-black-tree-set-3-delete-2/?ref=lbp
Red-Black tree re-balance strategies: 1. Recoloring; 2. Rotation . Recolor first, if not balanced then rotate.
https://www.geeksforgeeks.org/red-black-tree-set-2-insert/?ref=lbp
Java's TreeMap has a Red-Black tree implementation which allows it to do all basic operations in log(n) time while maintaining a sorted order of the elements. This makes it a decent alternative for PriorityQueue (Heap) for its remove(Object) method takes log(n), if there are decent amount of operations to remove Objects in the middle of the heap, since the PriorityQueue implemention remove(Object) takes O(n) to find the element to remove, then O(1) to remove and O(log(n)) to maintain the heap state.
AVL Tree¶
AVL tree is a self-balancing Binary Search Tree (BST) where the difference between heights of left and right subtrees cannot be more than one for all nodes.
The searching algorithm of an AVL tree is similar to that of a binary search tree, because of the property keys(left) < key(root) < keys(right).
Illustration of tree rotations which is critical for re-balancing the tree after each insertion/deletion operation.
T1, T2 and T3 are subtrees of the tree
rooted with y (on the left side) or x (on
the right side)
y x
/ \ Right Rotation / \
x T3 - - - - - - - > T1 y
/ \ < - - - - - - - / \
T1 T2 Left Rotation T2 T3
Keys in both of the above trees follow the
following order
keys(T1) < key(x) < keys(T2) < key(y) < keys(T3)
So BST property is not violated anywhere.
Let the newly inserted node be w
- Perform standard BST insert for w.
- Starting from w, travel up and find the first unbalanced node. Let z be the first unbalanced node, y be the child of z that comes on the path from w to z and x be the grandchild of z that comes on the path from w to z.
- Re-balance the tree by performing appropriate rotations on the subtree rooted with z. There can be 4 possible cases that needs to be handled as x, y and z can be arranged in 4 ways. Following are the possible 4 arrangements:
- y is left child of z and x is left child of y (Left Left Case)
- y is left child of z and x is right child of y (Left Right Case)
- y is right child of z and x is right child of y (Right Right Case)
- y is right child of z and x is left child of y (Right Left Case)
We only need to re-balance the subtree rooted with z and the complete tree becomes balanced as the height of subtree rooted with z becomes same as it was before insertion.
a) Left Left Case
T1, T2, T3 and T4 are subtrees.
z y
/ \ / \
y T4 Right Rotate (z) x z
/ \ - - - - - - - - -> / \ / \
x T3 T1 T2 T3 T4
/ \
T1 T2
b) Left Right Case
z z x
/ \ / \ / \
y T4 Left Rotate (y) x T4 Right Rotate(z) y z
/ \ - - - - - - - - -> / \ - - - - - - - -> / \ / \
T1 x y T3 T1 T2 T3 T4
/ \ / \
T2 T3 T1 T2
c) Right Right Case
z y
/ \ / \
T1 y Left Rotate(z) z x
/ \ - - - - - - - -> / \ / \
T2 x T1 T2 T3 T4
/ \
T3 T4
d) Right Left Case
z z x
/ \ / \ / \
T1 y Right Rotate (y) T1 x Left Rotate(z) z y
/ \ - - - - - - - - -> / \ - - - - - - - -> / \ / \
x T4 T2 y T1 T2 T3 T4
/ \ / \
T2 T3 T3 T4
Very similar to the insertion operation.
- Perform standard BST delete for w.
- Starting from w, travel up and find the first unbalanced node. Let z be the first unbalanced node, y be the larger height child of z, and x be the larger height child of y. Note that the definitions of x and y are different from insertion here.
- Re-balance the tree by performing appropriate rotations on the subtree rooted with z.
- Like insertion, the rotations operations are the same
- After fixing z, we may have to fix ancestors of z as well
https://www.geeksforgeeks.org/avl-tree-set-1-insertion/?ref=lbp
Heap¶
A heap is a tree-based data structure that is essentially a complete tree in the sense that new elements are always filling in the last level from left to right, then bobble up the tree.
Heap is only "partially sorted", that it can only yield a min/max value of all elements in the tree, one at a time. It is useful for repeatedly removing objects from the heap to get ordered output.
Heap can be easily implemented using an array. Each insert and remove operation takes O(log(n)). Thus for n elements it can take O(nlog(n)) sorting with a heap, which is how the Heap Sort got its name. Heapify an array using SiftDown approach (start from bottom of tree) takes O(n) to create the heap.

A tricky case where heap can be used is, given a matrix of numbers, how can you visit the numbers from the outter loop and closing in until all are visited, while always visit the smallest number possible.
It is also useful when dynamically calculate medians of a set of numbers that have numbers shift around.
In Java you can use PriorityQueue or TreeSet.
Signs for using Heap:
- Find the min or max from a given list of elements
- Find the kth largest/smallest
- When desires O(log(n)) for each operation
Signs for not using Heap:
- Find the closest value to some value (balanced BST)
- Find the min/max from a given range (Segment Tree)
- Use O(n) to find kth largest (Quick Select)
Trie¶
Trie is a special n-ary Tree that is good for solving problems that require finding strings of prefix, or word prediction.
Trie has great advantage over Maps when looking up a lots of words with common prefix; it requires much less Space.
Trie is great for use with DFS for solving complex problems. Be sure to know how to implement a Trie.
Signs for using a Trie:
- quick lookup if some word with certain prefix exists
- look for words in matrix of letters
Trie
Use as a helper class.
public class Trie {
boolean isWord;
Trie[] subTrie;
public Trie() {
// do intialization if necessary
this.isWord = false;
this.subTrie = new Trie[26]; // 26 for letter range a-z
}
public void insert(String word) {
// write your code here
Trie curr = this;
for (int i = 0; i < word.length(); ++i) {
char c = word.charAt(i);
Trie t = curr.subTrie[c - 'a'];
if (t == null) {
t = new Trie();
curr.subTrie[c - 'a'] = t;
}
curr = t;
}
curr.isWord = true;
}
private Trie findTrieWithPrefix(String prefix) {
Trie curr = this;
for (int i = 0; i < prefix.length(); ++i) {
char c = prefix.charAt(i);
Trie t = curr.subTrie[c - 'a'];
if (t == null) return null;
curr = t;
}
return curr;
}
public boolean search(String word) {
Trie target = findTrieWithPrefix(word);
return target == null ? false : target.isWord;
}
public boolean startsWith(String prefix) {
return findTrieWithPrefix(prefix) != null;
}
}
Segment Tree¶
Segment Tree is a binary tree data structure that can be used to calulate the sums of elements within a given index range in O(log(n)) time, while also allowing the data to be updated in O(log(n)) time. It is mostly represented in array form (can also be built in pure tree structure with increased complexity), and maintain these properties:
- root node represents the total sum of data (entire interval)
- leaf nodes are the elements of the input array
- each internal node (non-leaf) represents the sum of all of its leaf nodes within its range
- each child node represents about half the parent node's range
- for each node at index
iof the segment tree array, its left child is at2*i + 1, and right child at2*i + 2, and its parent at(i-1) / 2. - the size of the segment tree is bounded by
2 * 2^k - 1, wherekis the first number makes2^k >= n.
Segment Tree
The construction, update, sumRange operations are all done in recursive mannor.
class SegmentTree {
private int[] segTree;
private int n;
public SegmentTree(int[] nums) {
n = nums.length;
segTree = new int[n * 4]; // ensure enough capacity, proof https://stackoverflow.com/a/65300626/6037495
buildSegTree(nums, 0, 0, n-1);
}
private void buildSegTree(int[] nums, int treeIndex, int lo, int hi) {
if (lo == hi) {
segTree[treeIndex] = nums[lo];
return;
}
int mid = lo + (hi - lo) / 2;
buildSegTree(nums, 2 * treeIndex + 1, lo, mid); // fill left child
buildSegTree(nums, 2 * treeIndex + 2, mid + 1, hi); // fill right child
segTree[treeIndex] = segTree[2 * treeIndex + 1] + segTree[2 * treeIndex + 2];
}
public void update(int index, int val) {
updateSegTree(index, 0, 0, n-1, val);
}
private void updateSegTree(int numsIndex, int treeIndex, int lo, int hi, int val) {
if (lo == hi) {
segTree[treeIndex] = val;
return;
}
int mid = lo + (hi - lo) / 2;
if (mid < numsIndex) {
// look for numsIndex in the right half
updateSegTree(numsIndex, 2 * treeIndex + 2, mid + 1, hi, val);
}
else {
// look for numsIndex in the left half
updateSegTree(numsIndex, 2 * treeIndex + 1, lo, mid, val);
}
segTree[treeIndex] = segTree[2 * treeIndex + 1] + segTree[2 * treeIndex + 2];
}
public int sumRange(int left, int right) {
return sumSegTree(0, 0, n-1, left, right);
}
private int sumSegTree(int treeIndex, int lo, int hi, int i, int j) {
if (i > hi || j < lo) return 0;
if (i <= lo && j >= hi) return segTree[treeIndex]; // this seg range [lo, hi] should all be used in the sum
int mid = lo + (hi - lo) / 2;
// half of [lo, hi] are not relevant, shrink [lo, hi]
if (i > mid) { // use the right half, [i, j] unchanged
return sumSegTree(2 * treeIndex + 2, mid + 1, hi, i, j);
} else if (j <= mid) { // use the left half, [i, j] unchanged
return sumSegTree(2 * treeIndex + 1, lo, mid, i, j);
}
// now [i, j] contains mid of [lo, hi], tree them as two separate partitions
int leftSum = sumSegTree(2 * treeIndex + 1, lo, mid, i, mid);
int rightSum = sumSegTree(2 * treeIndex + 2, mid + 1, hi, mid + 1, j);
return leftSum + rightSum;
}
}
Sorting¶
Quick Sort¶
Quick Sort is a divide-and-conquer algorithm, sorts with O(nlog(n)) time.
It works by iterating log(n) times on the input array; in each iteration it chooses a pivot index which breaks the range into two partitions; then use two pointers from two ends of the range and swap numbers to ensure that numbers smaller than the pivot number are move to the left partition and those greater are moved to the right partition.
Quick Sort can be implemented in-place so it can sort in constant space. The choice of the pivot point can affect the effeciency of the algorithm depending on the data distribution.
Quick Sort is NOT a stable sort, however, unlike merge sort, which could be a trade off.
The Quick Select algorithm derived from Quck Sort borrows its partitioning thinking, which can be used to solve certain problems in O(log(n)) where sorting the list of items is not necessary.
Merge Sort¶
Merge Sort works by recursively divide the array into sub array of size 1, then on the way down the call stack, construct the merged and sorted subarrays.
Merge Sort is a stable sort. But it takes both O(nlog(n)) time and O(n) space to complete.
Count Sort¶
Count Sort works when the data range is finite and value set is small. Then it can take O(n) to sort the data by counting the appearance of each value, and lay out the values by expanding the counts.
Heap Sort¶
Heap Sort uses a Heap data structure to assist the sort operation. It takes O(nlog(n)) time and O(n) space to complete. It is in theory slower than other O(nlog(n)) approaches, since it in fact O(2nlog(n)) for the extra step in building the heap.
Dynamic Programming¶
Dynamic Programming (DP) is a mathematical optimization method to break down a large and complicated problem into smaller and simpler sub-problems, then build each sub-problem upon results from previous ones.
Signs for using DP:
- find number of ways to do something
- find the min/max of some value(s) that satisfy some condition
- find if some action can be completed
Possibly not a DP solution:
- finding concrete set of solutions that satisfy some condition (DFS)
- given input is unsorted
There are four fashions for Dynamic Programming thinking:
- Rolling Update on an array or matrix of numbers
- use previous result to build next result, how to get there
- how to initialize the state and starting point
- where does the final answer lies
- the key is to find what does the dp value represent, what are transition from state to the next state, and how to initialize the dp values before iterating (the extreme or end cases)
- Memorization of state
- when some state repeats within the sub-problems, calculate it once and save its result for use in future occurrances
- the core is dfs
- Strategy Game dp
- having a greedy smart opponent, whether you can win a game
- state transition involes considering my max gain and opponent's max gain
- Backsack dp
- use values as the dimension of the dp matrix
The signs for dynamic programming problems: get the min/max, whether there exists some value, how many of something exists, that that satisfy some condition.
DP often requires setting up a 1D array or 2D matrix to track the result of sub-problem as the two changing factors updates. It can grow to 3D or more depends on the number of changing factors to consider.
Space optimization: usually 2D matrix is suffice, there may be opportunity to cut it down to 1D array since we mostly care about the previous row in a DP matrix. For problems solved intuitively using 1D array DP, you can cut it down to just 2-3 variables.
There are no fixed way to solve anything with DP. The key is to think in DP.
Technique to optimize the rolling update numbers in array/matrix
public void problem() {
// size n matrix
f[i] = Math.max(f[i-1], f[i-2] + A[i]);
// as size 2 matrix
f[i % 2] = Math.max(f(i-1) % 2, f[(i-2) % 2)
// or just use two intuitive variables
}
Some problems define relationships for a cell with its four neighbors and look for a maximum value that satisifies a condition. For this we can do memorization, pseudo code:
dp = new int[m][n]
for i = 1 -> m
for j = 1 -> n
search (i, j)
search(int x, int y, int[][]A)
if (dp[x][y] == 0) return;
dp[x][y] = 1
for i = 1 -> 4
nx = x + dir[0]
ny = y + dir[1]
if ( A[x][y] < A[nx][ny] ) // depends on the required condition
search(nx, ny, A) // ensure it is filled
dp[x][y] = max(dp[x][y], dp[nx][ny] + 1) // depends on the condition
The memorization is very useful when it is hard to determine the steps for state change, or defining the initial state. Its key is to take down large range and work on its smaller units and memorize and go back up, work on [0, n-1] at last. It often needs recursion to simplify the code.
A third type of DP problem involes thinking with a greedy opponent playing a game with you. You need to work from the end of the game to the beginning of the game to get the result, as it is easier to see the decision being made when close to end of game. The initial state are actually the state for end of the game, as we are working from the subset closing to the end of the game back to the beginning of the game to know whether we win or lose.
Take Coins in a Line problem as an example:
- when facing no coin in the end, we get nothing,
dp[n] = 0- index i means how many coins has been taken
- when facing last coin, we take it,
dp[n-1] = values[n-1] - when facing last two coins, we take both (greedy),
dp[n-2] = values[n-2] + values[n-1] - when facing last three coins, we take two, otherwise opponent will take two,
dp[n-3] = values[n-3] + values[n-2] - when facing four and more coins, things get interesting, as we can take one or two
- if only take one, you can assume the opponent is smart in maximizing his gain so he will choose wisely to take whether one or two
- thus our gain will be
dp[i] = values[i] + min(dp[i+2], dp[i+3]), the min function must be used here as the opponent may take one or two to minimize your gain
- thus our gain will be
- if take two, for the same reason above
- our gain will be `dp[i] = values[i] + values[i+1] + min(dp[i+3], dp[i+4])
- if only take one, you can assume the opponent is smart in maximizing his gain so he will choose wisely to take whether one or two
- dp[0] will be the max gain we get from playing the game.
- to see whether we win, calculate coins sum and use
sum - dp[0] < dp[0]
- to see whether we win, calculate coins sum and use
A fourth type of DP problem is backsack problems. The key is to think about using range of values as one of the dimensions tracked with DP.
Example problem: given a list of items with weights and values, maximize the total value put in a sack without going off the weight limit. Here the "value range dimension" is the max allowed weights.
There are two factors: how many items we can choose from, and max weight we cannot go over. Then we work bottom up to figure out the max value at max allowed weights to choose from all items.
Again, it is crucial to realize how dp matrix can be used and represent the steps. dp[i][j] will mean if I have first i items to choose from, and the max weight is j, what is the max gain. First get the solution out, then simplify the space complexity.
The state transition involves thinking if take the current item or not:
- not take:
- dp[i][j] = dp[i-1][j]
- do take:
- dp[i][j] = Math.max(dp[i-1][j], dp[i-1][j-num])
- in the condition when you can repeatedly take some num:
dp[i][j] += dp[i-1][j - num * k], where k = 0~v where k*v <= j- basically we are trying to see, if we take one, two, or more of the same num, can be get more combinations
DFS¶
Depth-First-Search (DFS) is an algorithm good for searching within a tree, a graph, or backtrack iterating through elements in an array. DFS is mostly implemented recursively.
Pay attention to when the order of elements affect the condition for going deeper, what does duplicate elements mean for the algorithm. Sometimes it helps to use Set or Map to memorize and to avoid revisiting the same path seen before.
Signs for using DFS:
- Find all solutions that satisify some condition
- Binary Tree traversal
- Permutation problems (list order does not matter)
- Arrangement problems (list order matters)
BFS¶
Breath-First-Search (BFS) is an algorithm good for level-order traversing trees, topology sort, search in graphs.
BFS can be implemented iteratively using a Queue. Consider use Set to track node visited, or Map to track distances between visited nodes. Some problems can be optimized using two BFS traversing from two ends to reduce number of nodes visited.
Signs for using BFS:
- Topology sort
- Tree level order traversal
- Shortest path in graph
- Fewest moves to get to a state, given a state-change function
- When elements in a data structure are connected in some way
- Where there is a clear BFS solution, iteration may be more efficient than recursive DFS
Special Algorithms¶
Binary, Binary Search¶
Binary search is an extremely useful algorithm to narrow down a large set of data and find the desired result that satisfy a certain condition. It usually can do O(logn) for an already sorted data set. Its key is to eliminate half of the data where the answer is not in.
The the target could be a certain number, or a min/max value.
Also note the binary search is NOT necessarily always must be applied on an array of numbers. It can be just a pair of bounds [a, b], where your job is to find some value between [a, b] satisfy a condition, and maybe find the smallest/largest possible value. Binary thinking still applies. The Strategy:
- Find the solution range [a, b]
- guess from the middle of range, verify condition
- if condition not met, continue search while cut down range by half
The Condition part of this problem usually can be the difficult part. It is not hard to realize the binary approach after all. This conditional verification can take O(n) to complete, thus brings overall to O(nlog(n)). When working on some problem where the clear brute-force approach takes O(n^2), try thinking in this direction see if you can come up with something.
Signs for using binary search:
- search in ordered list
- when time complexity requires better than O(n)
- when a list can be partitioned into two parts, where answer lies in one part
- find a max/min value to satisfy a certain condition
Binary Search
Basic form, good for when we know there is only one index may satisfy the condition.
public void binarySearch() {
// check edge case when nums is empty
int lo = 0, hi = n - 1;
while (lo <= hi) {
int mid = lo + (hi - lo) / 2;
if (nums[mid] == target) // condition might differ
return mid;
else if (nums[mid] < target) {
lo = mid + 1;
} else {
hi = mid - 1;
}
}
return -1; // not found
}
Another form, good for looking for a min/max index that satisfy the condition.
public void binarySearch() {
// check edge case when nums is empty
int lo = 0, hi = n - 1;
while (lo < hi) {
int mid = lo + (hi - lo) / 2;
if (nums[mid] >= target) {
hi = mid; // now we are looking smallest i that nums[i] == target
} else {
lo = mid + 1;
}
}
return nums[hi] == target ? hi : -1; // not found
}
Yet another form which may work better, as binary always end up with two values, lo and hi; then use an additional condition to check which one to use.
public int binarySearch() {
// check edge case when nums is empty
int lo = 0, hi = n - 1;
while (lo < hi - 1) {
int mid = lo + (hi - lo) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
lo = mid;
} else {
hi = mid;
}
}
if (lo < target) return lo;
return hi;
}
Two Pointers¶
Some common signs for two pointers:
- Sliding window, when need to inspect a range of numbers/characters
- i.e. inspect subarray/substring
- When the most optimal time complexity is O(n)
- When we want to use no extra space to solve
- Palindrome problems
The two pointers can move in the same direction or the opposite direction
Sliding Window¶
Sliding Window
Most problems follow this template
public void problem() {
for (int lo = 0, hi = 0; lo < n; ++lo) {
while (hi < n && condition) {
++hi;
// some logic related to after hi is increased
// like update a tracker variable
}
// nothing found, no need to move lo
if (above condition was still "false")
break;
// some logic related to current lo value
}
}
Topology Sort¶
Classical problem where dependency relationships are clear. Topology sort sorts the Nodes within a Directed Acyclic Graph in an order that does not violate the edges relations.
Topology sort
L = Empty list that will contain the sorted elements
S = Set of all nodes with no incoming edge
while S is non-empty do
remove a node n from S
add n to tail of L
for each node m with an edge e from n to m do
remove edge e from the graph
if m has no other incoming edges then
insert m into S
if graph has edges then
return error (graph has at least one cycle)
else
return L (a topologically sorted order)
Disjoint Sets for Union Find¶
Union Find with Disjoint Sets is used to solve problems that require
- check if two elements are within the same sets
- union the two sets represented by the two elements
- convert all other operations to follow the above two rules
It allows doing find and union operations in O(1) time on average.
- find - check if two elements are within the same set
- union - combine two sets
Union Find
Use as a helper class.
public static class UnionFind {
int[] parent;
public UnionFind(int size) {
parent = new int[size];
for (int i = 1; i < size; ++i)
parent[i] = i; // parent[i] == i means index i is its own root
// other strategy: Arrays.fill(parent, -1) means -1 denotes a root index
}
public int find(int i) {
if (parent[i] == i)
return i; // i's root is i
parent[i] = find(parent[i]); // path compression
return parent[i];
}
public void union(int x, int y) {
int xRoot = find(x);
int yRoot = find(y);
if (xRoot != yRoot) {
// let smaller index root point to higher index root
parent[Math.min(xRoot, yRoot)] = Math.max(xRoot, yRoot);
}
}
}
Some tricks depends on the need of the problem:
- initialize the parent list:
- initialize all to '-1' to denode it is its own parent
- initialize all to its index to denode it is its own parent
- union, when two are disjoint, which should join which?
- min -> max
- max -> min
- smaller -> larger
Kth Largest in N Arrays¶
Sort the arrays, then use Heap; insert first column to a heap, then pop out a number and insert a new number ensuring it is the next smallest number (by tracking the x,y of the popped number); repeat k times to get the kth smallest.
Time is mostly O(m * nlog(n)) for sorting and O(klog(min(k, m, n))) for Heap operations.
Sweep line¶
This type of problems have a common sign that you have to determine the max number of overlapping intervals at all time from the given intervals.
To solve it in O(n), first create a list to put all intervals numbers together (thus start and end form a line), then sort them base on the first number, then by whether it is the start or end. Then iterated from first to last, count the start number and reduce when end number is reached.
The problem can get more complex, i.e. having additional parameter to consider and sort. But in the end it just adds more cases to consider, the core idea remains the same.
Shortest Path¶
Given a graph and a source vertex in the graph, find the shortest paths from the source to one or all vertices in the given graph.
Dijkstra¶
All nodes within the graph must be connected.
Dijkstra's algorithm solves this problem in O(u * v). We keep a set to track visited vertices, and a another map to track the minimal distance from source to every other vertice.
It works by starting from a node/vertice then update its immediate neighbors distance with the distance to current node + edge cost to that neighbor, then move on to the next unvisited node with minimal distance, then repeat until all nodes are visited.
The algorithm:
- first make the adjacency matrix or adjacency list out of the graph.
- initialize a
visitedSetto track visited vertices - initialize
minDistanceMapas empty and only keeps finite minDistances, assume unvisited vertices are Infinity distance if it is not in the Map - set source minDistance to 0 by adding it to
minDistanceMap - while there is any vertice unvisited
- for each unvisited vertice with finite minDistance, choose one
vthat has the minimal distance - set
vas visited by adding it to thevisitedSet - remove
v's minDistance fromminDistanceMap - check
v's immediate neighborsuthat are unvisited- now
vtoudistancedisv's minDistance + edge cost tou - if
u's minDistance is Infinity, setu->dinminDistanceMap - if
u's minDistance is finite but larger thand, update this value inminDistanceMap
- now
- for each unvisited vertice with finite minDistance, choose one
Iterator implementation¶
When implementing iterator for data structures that may contain nested structure, we need to avoid the hell of recursively getting the whole structure built at once either at the constructor or next() method.
To keep it fast on average, we should move the buffering stage to the hasNext() method, and have next() invoke hasNext() before pulling next value. Meanwhile, keep a Stack and ensure its top value is ready to be accessed. If it is a nested structure, the process (flatten) it so it can be accessed directly next. Use the help of a temporary stack to pour the nested items on top of current stack in a first-in-first-out mannor.
Big O Calculation¶
For loops that go through all elements once takes O(n), each dimention of nested loop increases O(n)'s power by one. Note that depends on the algorithm, mixed use of loops and recursion may also increase the O(n)'s power.
For binary search when we can eliminate half of the results at each step, it takes O(log(n)) to narrow down to the result.
For clear evidence of continuous time complexity of O(n + n/2 + n/4 + ... + 1) is roughly O(n) on average.
Note that when processing strings or arrays, string copy or array copy may easily add O(n) to both time and space complexity.