Google SRE Book
Notes taken from Google SRE Book.
Software engineering has this in common with having children: the labor before the birth is painful and difficult, but the labor after the birth is where you actually spend most of your effort.
SREs are focused on operating services built atop the distributed computing systems that span globally across multiple regions and serve millions to billions of users.
Much like security, the earlier you care about reliability, the better.
Concept of Dev, Ops, and DevOps¶
This systems administrator, or sysadmin, assembles existing software components (developed by the developers) and deploying them to produce a service, runs the service, and responds to events and updates as they occur. These tasks generally fall into the category of operations. Developers and sysadmins are therefore divided into discrete teams: "development/dev" and "operations/ops".
As the system grows in complexity and traffic volume, generating a corresponding increase in events and updates, the sysadmin team grows to absorb the additional work and increases operational cost, which is a direct cost.
The indirect costs arise from the fact that the two teams are quite different in background, skill set, and incentives. They use different vocabulary to describe situations; they carry different assumptions about both risk and possibilities for technical solutions; they have different assumptions about the target level of product stability.
At their core, the development teams want to launch new features and see them adopted by users; the ops teams want to make sure the service doesn’t break while they are holding the pager.
DevOps is a set of principles guiding software development: involvement of the IT function in each phase of a system’s design and development, heavy reliance on automation versus human effort, the application of engineering practices and tools to operations tasks.
SRE¶
How SRE Differs from DevOps¶
DevOps's principles and practices are consistent with Site Reliability Engineering. DevOps is a generalization of several core SRE principles to a wider range of organizations, management structures, and personnel.
In general, an SRE team is responsible for the availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of their service(s).
Site Reliability Engineering teams focus on hiring software engineers to deploy and run products and to create systems to automate work that otherwise would be performed manually.
This structure also improves the product development teams: easy transfers between product development and SRE teams cross-train the entire group.
UNIX system internals and networking (Layer 1 to Layer 3) expertise are the two most common types of alternate technical skills for software engineers hired into SRE roles. A diverse background of the SRE team frequently results in clever, high-quality systems.
Google places a 50% cap on the aggregate "ops" work for all SREs—tickets, on-call, manual tasks to ensure SRE team can focus on engineering work in building or improving existing systems.
Eliminating toil is one of SRE’s most important tasks. Systems should be automatic, not just automated. They should run and repair themselves.
Postmortems should be written for all significant incidents, regardless of whether or not they paged; postmortems that did not trigger a page are even more valuable, as they likely point to clear monitoring gaps. Google operates under a blame-free postmortem culture, with the goal of exposing faults and applying engineering to fix these faults, rather than avoiding or minimizing exposing them.
Error budget¶
Product development and SRE teams can enjoy a productive working relationship by eliminating the structural conflict in their respective goals between pace of innovation and product stability, with an agreed error budget.
A service that’s 99.99% available is 0.01% unavailable. That permitted 0.01% unavailability is the service’s error budget. 100% error budget is the wrong reliability target for basically everything. Setting the correct error budget is a product question and should consider:
- level of availability to keep user satisfied
- alternatives for unhappy users with given availability
- user's accessible features of product at different availability levels
Spend error budget taking risks with things to launch. As soon as SRE activities are conceptualized in this framework, freeing up the error budget through tactics such as phased rollouts and 1% experiments can optimize for quicker launches.
An outage is no longer a "bad" thing—it is an expected part of the process of innovation, and an occurrence that both development and SRE teams manage rather than fear.
Monitoring¶
Monitoring allows service owners keep track of a system’s health and availability. Traditionally, monitoring watches for a specific value or condition, and then triggers an alert to engineers when that value is exceeded or that condition occurs.
Monitoring should never require a human to interpret any part of the alerting domain. Instead, software should do the interpreting, and humans should be notified only when they need to take action.
Alerts should be sent when immediate actions need to be taken by an engineer. Tickets should be issued when engineers action is required but not immediately. Logging should be recorded for diagnostic or root-cause-analysis purposes.
Oncall, Emergency Response¶
Reliability is a function of mean time to failure (MTTF) and mean time to repair (MTTR). Humans add latency. A system that can avoid emergencies that require human intervention will have higher availability than a system that requires hands-on intervention.
Thinking through and recording the best practices ahead of time in a "Runbook" that gives each possible fail case and steps for remediation, drastically improves the MTTR for incidents that involves human.
Change Management¶
Best practices implementing automation around changes:
- apply progressive rollouts
- detect problems quickly and accurately
- roll back changes safely and quickly upon detecting problems
Capacity Planning¶
Demand forecasting and capacity planning can be viewed as ensuring that there is sufficient capacity and redundancy to serve projected future demand with the required availability.
Capacity planning should take both organic growth (natural product adoption from users) and inorganic growth (feature launches, marketing campaigns) into account.
Regular load testing of the system should be performed to correlate raw resource capacity to service capacity.
Provisioning¶
Provisioning combines both change management and capacity planning. Provisioning must be conducted quickly and only when necessary, as capacity is expensive.
Adding new capacity often involves spinning up a new instance or location, making significant modification to existing systems (load balancers, networking, configurations changes), and validating that the new capacity performs and delivers correct results.
Efficiency and Performance¶
Resource utilization provides insights of a service's efficiency, and is a function of demand (load), capacity, and software efficiency. SREs predict demand, provision capacity, and can modify the software.
Software systems become slower as load is added to them. A slowdown in a service equates to a loss of capacity. At some point, a slowing system stops serving, which corresponds to infinite slowness.
SREs provision to meet a capacity target at a specific response speed (responses per second), and thus are keenly interested in a service’s performance.
SREs and product developers will (and should) monitor and modify a service to improve its performance, thus adding capacity and improving efficiency.
Production Environment¶
In a production environment, a machine refers to a piece of hardware or VM and a server refers to a piece of software that implements a service. Machines can run any server.
Topology of a Google datacenter:
- Tens of machines are placed in a rack.
- Racks stand in a row.
- One or more rows form a cluster.
- Usually a datacenter building houses multiple clusters.
- Multiple datacenter buildings that are located close together form a campus.
Managing Machines¶
Borg is a distributed cluster operating system managing user jobs at the cluster level and allocate resources to jobs.
Jobs can either be indefinitely running servers or batch processes like a MapReduce. Borg then continually monitors these tasks. If a task malfunctions, it is killed and restarted, possibly on a different machine.
Borg allocates a name and index number to each task using the Borg Naming Service (BNS). Rather than using the IP address and port number, other processes connect to Borg tasks via the BNS name, which is translated to an IP address and port number by BNS.
Storage¶
The storage layer is responsible for offering users easy and reliable access to the storage available for a cluster:
- the lowest layer is called D (disk), a fileserver running on almost all machines in a cluster
- Colossus layer is on top of D and creates a cluster-wide filesystem that offers usual filesystem semantics, as well as replication and encryption
- next layer are several database-like services
- Bigtable, NoSQL database handles petabyte-grade data. It is a sparse, distributed, persistent multidimensional sorted map that is indexed by row key, column key, and timestamp; each value in the map is an uninterpreted array of bytes. Bigtable supports eventually consistent, cross-datacenter replication.
- Spanner, SQL-like distributed database for real consistency across the world
- Blobstore
Networking¶
Instead of using "smart" routing hardware, Google rely on less expensive "dumb" switching components in combination with a central (duplicated) controller that precomputes best paths across the network.
Google directs users to the closest datacenter with available capacity. Our Global Software Load Balancer (GSLB) performs load balancing on three levels:
- geographic DNS requests
- user service (i.e. YouTube, Google Maps)
- RPC level
Locking¶
The Chubby lock service provides a filesystem-like API for maintaining locks. It uses the Paxos protocol for asynchronous Consensus.
Chubby helps master election and provides a consistent storage.
Monitoring¶
Borgmon monitoring proram regularly scrapes metrics from monitored servers. These metrics can be used instantaneously for alerting and also stored for use in historic overviews.
Software infrastructure¶
Google software architecture is designed to make the most efficient use of the hardware infrastructure. Code is heavily multithreaded. Every server has an HTTP server that provides diagnostics and statistics for a given task.
All of Google’s services communicate using a Remote Procedure Call (RPC) infrastructure named Stubby (opensourced as gRPC).
Often, an RPC call is made even when a call to a subroutine in the local program needs to be performed. This makes it easier to refactor the call into a different server if more modularity is needed, or when a server’s codebase grows.
A server receives RPC requests from its frontend and sends RPCs to its backend. Data is transferred to and from an RPC using protocol buffers (protobufs).
Protocol buffers have many advantages over XML for serializing structured data: they are simpler to use, 3 to 10 times smaller, 20 to 100 times faster, and less ambiguous.
Development Environment¶
Development velocity is very important to Google. Google Software Engineers work from a single shared repository.
If engineers encounter a problem in a component outside of their project, they can fix the problem, send the proposed changes ("changelist/CL", like a PR) to the owner for review, and submit (merge) the CL to the mainline.
Changes to source code in an engineer’s own project require a review. All software is reviewed before being submitted.
When software is built, the build request is sent to build servers in a datacenter and executed in parallel. Each CL submition causes tests to run on all software that may depend on that CL. Some projects use a push-on-green system, where a new version is automatically pushed to production after passing tests.
Shakespeare¶
Shakespeare: a sample service at google
Principles¶
A key principle of any effective software engineering, not only reliability-oriented engineering, simplicity is a quality that, once lost, can be extraordinarily difficult to recapture.
Embracing Risk¶
Cost does not increase linearly as reliability increments: an incremental improvement in reliability may cost 100x more than the previous increment. The cost comes from:
- redundant machine and computing resources
- opportunity cost for building systems or features usable by end users
Measuring risks¶
SRE manages service reliability largely by managing risk, conceptualizes risk as a continuum, and identifies the appropriate level of risk tolerance for the services to run.
Service failures can have many potential effects, including user dissatisfaction, harm, or loss of trust; direct or indirect revenue loss; brand or reputational impact; and undesirable press coverage.
For most services, the most straightforward way of representing risk tolerance is in terms of the acceptable level of unplanned downtime and is expressed by service availability in terms of number of "nines": 99.9%, 99.99%, etc. The availability can be calculated as (uptime / uptime + downtime) or (successful requests / total requests). The same principles also apply to nonserving systems with minimal modification.
Risk tolerance¶
Product managers are charged with understanding the users and the business, and for shaping the product for success in the marketplace. To identify the risk tolerance of a service, SREs must work with the product owners to turn a set of business goals into explicit objectives that can be engineered.
Factors to consider on consumer services:
- required level of avalilability
- users' expectation
- impact on our revenue, or our users' revenue
- paid or free service
- how much does our competitors set
- is the service target consumers or enterprises
- does different types of failures have different effects on the service
- business resilience on service downtime
- impact from low rate of failures, or occasional full-site outage
- planned downtime
- locate a service cost on the risk continuum
- what would be the increase in revenue and the cost to increase the availability
- move forward when the revenue increase offsets the implementation cost
- service metrics to account for
- understand the importance of metrics under different use cases and focus on those important ones
Error Budgets¶
Error budget provides a common incentive that allows both product development and SRE to focus on finding the right balance between innovation and reliability.
The tensions between feature delivery and site reliability reflect themselves in different opinions about the level of effort that should be put into engineering practices:
- software fault tolerance
- testing
- release frequency
- canary duration and size
The Service Level Objectives express error budget in a clear, objective metric that determines how unreliable the service is allowed to be within a single quarter.
- Product Management defines an SLO of expected uptime for the quarter
- Monitoring system measure the actual uptime
- The difference between the budget and the unreliability happened tells the remaining budget for the quarter
- As long as there are budget remaining, new releases can be pushed
For example, imagine that a service’s SLO is to successfully serve 99.999% of all queries per quarter. This means that the service’s error budget is a failure rate of 0.001% for a given quarter. If a problem causes us to fail 0.0002% of the expected queries for the quarter, the problem spends 20% of the service’s quarterly error budget.
If product development wants to skimp on testing or increase push velocity and SRE is resistant, the error budget guides the decision. When the budget is large, the product developers can take more risks. When the budget is nearly drained, the product developers themselves will push for more testing or slower push velocity, as they don’t want to risk using up the budget and stall their launch.
Service Level Terminology¶
Indicators (SLI) - a carefully defined quantitative measure of some aspect of the level of service that is provided. i.e. request latency, error rate, system throughput or rps. These metrics are often aggregated into a rate, average, or percentile.
Understanding of what your users want from the system will inform the judicious selection of a few indicators:
- user-facing: availability, latency, throughput
- storage systems: latency, availability, durability
- big data systems, data pipelines: throughput, end-to-end latency
- generally for all systems: correctness
Objectives (SLO) - a target value or range of values for a service level that is measured by an SLI.
For maximum clarity, SLOs should specify how they’re measured and the conditions under which they’re valid. i.e. 99% (averaged over 1 minute) of Get RPC calls will complete in less than 100 ms (measured across all the backend servers).
Choose just enough SLOs to provide good coverage of your system’s attributes. Get rid of unnecessary SLOs that cannot indicate priorities.
Keep a safety margin, use a tighter internal SLO than the SLO advertised to users gives you room to respond to chronic problems before they become visible externally. You can always refine SLO definitions and targets over time as you learn about a system’s behavior. Start loose and tighten it later.
Don't overachieve. If your service’s actual performance is much better than its stated SLO, users will come to rely on its current performance.
Understanding how well a system is meeting its expectations helps decide whether to invest in making the system faster, more available, and more resilient, on tasks such as paying off tech debts, adding new features, introducing other tools, workflows, or products.
Agreements (SLA) - an explicit or implicit contract with your users that includes consequences of meeting (or missing) the SLOs they contain.
The consequences are most easily recognized when they are financial: a rebate or a penalty—but they can take other forms. SLAs are closely tied to business and product decisions.
It is wise to be conservative in what you advertise to users, as the broader the constituency, the harder it is to change or delete SLAs that prove to be unwise or difficult to work with.
Indicators processing¶
Indicator metrics are most naturally gathered on the server side using a monitoring system or with periodic log analysis. Some should be instrumented with client-side collection, because not measuring behavior at the client can miss a range of problems that affect users but don’t affect server-side metrics.
Most metrics are better thought of as distributions or percentiles rather than averages. For example, a simple average latency metric aggregated over a fixed window can obscure these tail latencies, as well as changes in them. Alerting based only on the average latency would show no change in behavior over the course of the day, when there are in fact significant changes in the tail latency.
User studies have shown that people typically prefer a slightly slower system to one with high variance in response time.
Indicators should be standardized to avoid repeated reasoning each time they are needed. i.e. make it a template:
- aggregation window/interval size: 1 minute
- aggregation region: all within a cluster
- measurement frequency: every 10 seconds
- requests measured: HTTP GETs on xxx API
- data collection: monitoring framework measured at the server
- data access latency: time to last byte received since request sent
Eliminate Toil¶
Overhead is often work not directly tied to running a production service, and includes tasks like team meetings, setting and grading goals, snippets, and HR paperwork.
Toil is the kind of work tied to running a production service that tends to be:
- manual, such as manually running some commands or a script that completes some task
- repetitive, the work you do over and over manually
- automatable, when machines can do the task as well as human without relying on a human's judgement for choices
- tactical, interrupt-driven and reactive, rather than strategy-driven and proactive. i.e. pager duty is inevitable but with opportunity to minimize
- no enduring value, so the service remains in the same performance state after you have finished a task
- scales linearly as a service grows. Ideally the service should be able to grow by one order of magnitude with zero manual work to add resource
Toil tends to expand if left unchecked and can quickly fill 100% of everyone’s time. SRE's engineering work either reduce future toil or add service features. Feature development typically focuses on improving reliability, performance, or utilization, which often reduces toil as a second-order effect.
SREs report that their top source of toil is interrupts (that is, non-urgent service-related messages and emails). The next leading source is on-call (urgent) response, followed by releases and pushes.
Typical SRE duties¶
- Software engineering - writing or extending code, design document, or software documentation.
- i.e. automation scripts, developing tools or frameworks, adding service features for scalability and reliability, hardening service with infrastructure code
- System engineering - configuring production systems, modifying configurations, or documenting systems runbooks
- i.e. setting up monitoring, load balancer configuration, server configuration, tuning OS parameters, productionization for dev teams
- Toil - repetitive work in running a service
- i.e. mentioned in above section
- Overhead - administrative work not tied directly to running a service
- i.e. hiring, HR paperwork, trainings, meetings, peer reviews and self-assess
Toil isn’t always and invariably bad, and some amount of toil is unavoidable in any engineering role. Small amount of toil can be calming and rewards with a sense of quick wins. Toil becomes toxic when experienced in large quantities.
If we all commit to eliminate a bit of toil each week with some good engineering, we’ll steadily clean up our services, and we can shift our collective efforts to engineering for scale, architecting the next generation of services, and building cross-SRE toolchains.
Monitoring¶
Monitoring terminologies:
- monitoring - collecting, processing, aggregating, and displaying real-time quantitative data about a system
- white-box monitoring - base on metrics exposed by the internals of the system, such as logs
- black-box monitoring - testing externally visible behavior as a user would see it, such as end-to-end testing
- dashboard - an application provides a summary view of a service's core metrics
- alert - a notification intended to be read by a human and that is pushed to a system such as a bug or ticket queue, an email alias, or a pager
- root cause - a defect in a software or human system that, if repaired, instills confidence that this event won’t happen again in the same way
- node, machine - used interchangeably to indicate a single instance of a running kernel in either a physical server, virtual machine, or container
- push - any change to a service’s running software or its configuration.
Monitoring helps:
- analyzing long-term trends
- comparing over time or experiment groups
- alerting
- building dashboards
- ad hoc retrospective analysis
- business analytics
- security analysis
Effective alerting systems have good signal and very low noise (unnecessary pages). Rules that generate alerts for humans should be simple to understand and represent a clear failure.
Paging a human is a quite expensive use of an employee's time. When meaningless pages occur too frequently, employees second-guess, skim, or even ignore incoming alerts. Outages can be prolonged because other noise interferes with a rapid diagnosis and fix.
Every page should be about a novel problem and actionable and require intelligence. Someone should find and eliminate the root causes of the problem.
Pages with rote, algorithmic responses should be a red flag. Unwillingness on the part of your team to automate such pages implies that the team lacks confidence that they can clean up their technical debt (i.e. put in quick short term fixes to automate the page response, but plan for a long term fix). This is a major problem worth escalating.
Symptoms vs. Causes¶
Your monitoring system should address two questions: what’s broken, and why?
For example, high 5xxs maps to a part of service is down or behaving unexpectedly; high latency maps to one of overloaded server, low network bandwidth, or packet loss; users in a region seeing service interruptions maps to blocked traffic or a network partition; private content made public maps to missing ACLs in configurations.
Black-box monitoring is symptom-oriented and represents active problems. White-box monitoring depends on the ability to inspect the innards of the system with instrumentation and allows detection of imminent problems such as failures masked by retries.
If web servers seem slow on database-heavy requests, you need to know both how fast the web server perceives the database to be, and how fast the database believes itself to be. Otherwise, you can’t distinguish an actually slow database server from a network problem between your web server and your database.
The four golden signals of monitoring:
- Latency - time it takes to service a request, and distinguish between successful and failed requests
- Traffic - service demand on the system, such as high level requests per second broken down by nature of request
- Errors - rate of requests that fail explicitly, implicitly (succeed but delivers wrong content), or by policy (rate limit policy)
- Saturation - how "full" the service is serving from its capacity.
- many systems degrade in performance before they achieve 100% utilization, utilization target should be set appropriately below 100%
- saturation is also concerned with predictions of impending saturation, i.e. at current rate, the disk will fill in about 4 hours.
The simplest way to differentiate between a slow average and a very slow "tail" of requests is to collect request counts bucketed by latencies (rendering a histogram). Distributing the histogram boundaries approximately exponentially.
Monitoring Resolutions¶
Different aspects of a system should be measured with different levels of granularity. Very frequent measurements may be very expensive to collect, store, and analyze. As an example for an alternative way for high-granularity metric data:
- record the metric value each second
- use buckets of 5% granularity, increment the appropriate metric bucket each second
- aggregate those values every minute
This strategy allows observing brief CPU hotspots without incurring very high cost due to collection and retention.
Design your monitoring system with an eye toward simplicity:
- rules for alerting for incidents should be as simple, predictable, and reliable as possible
- data collection, aggregation, and alerting configuration that is rarely exercised should be up for removal
- signals that are collected, but not exposed in any prebaked dashboard nor used by any alert, are candidates for removal
- alerts should be actionable. If some condition is not actionable then they should not be alerts. Add filters to apply non-actionable conditions
- alerts should reflect its urgenciness and it should be easy to tell if it can wait until working hours for remediation
- make sure the same cause does not page multiple teams, causing duplicate work. Others can be informed but not paged. Alerts should page the most relevant teams.
In Google’s experience, basic collection and aggregation of metrics, paired with alerting and dashboards, has worked well as a relatively standalone system.
It’s better to spend much more effort on catching symptoms than causes; when it comes to causes, only worry about very definite, very imminent causes.
Actionable alerts should result in work to automate the actions or fix real issues. While short-term fix can be acceptable, long-term fix should also be tracked instead of getting forgotten and regression happens. Pages with rote, algorithmic responses should be a red flag.
Achieving a successful on-call rotation and product includes choosing to alert on symptoms or imminent real problems, adapting your targets to goals that are actually achievable, and making sure that your monitoring supports rapid diagnosis.
Automation¶
Software-based automation is superior to manual operation in most circumstances, although doing automation thoughtlessly can create as many problems as it solves.
Value of automation¶
- scales with the system
- consistency in executing procedures and results
- can evolve into a platform, extensible for more use cases and for profit, and adding monitoring and extract metrics
- faster than manual work, reduce mean time to repair (MTTR) and time to action
- massive amount of human time savings
For truly large services, the factors of consistency, quickness, and reliability dominate most conversations about the trade-offs of performing automation.
Reliability is the fundamental feature, and autonomous, resilient behavior is one useful way to get that.
Use cases¶
- manage machines user accounts
- cluster scaling up and down
- software/hardware installation, provision, or decommission
- new software version rollout
- runtime configuration updates
- runtime dependency updates
- etc.
A hierarchy of automation classes, taking service failover as an example:
- no automation, manual failover that touches multiple places
- externally maintained specific automation, i.e. a script owned by some SRE engineer to do failover one specific system
- externally maintained generic automation, a generic tool that can be used to failover any system that is properly onboarded
- internally maintained specific automation, i.e. a database's own failover mechanism that can be used for failover, but managed by the database owner
- system that needs no automation, or automatically detects faults and carries out the failover
Automation needs to be careful about relying on implicit "safety" signals or it can make unwanted changes that may potentially harm your system.
Case studies¶
Google Ads SRE - MySQL on Borg: Borg's infrastructure does frequent restarts and shifting jobs around to optimize resource utilization. MySQL instances gets interrupted a lot on Borg. Quick failover becomes a requirement. The SRE team developed a daemon to automate the failover process and made the system highly available on Borg. It did come with a cost that all MySQL dependencies must implement more failure-handling logic in their code. The win is still obvious in hardware savings (60%), and hands-free maintenance.
Cluster Infra SRE - Cluster Turnups: Setting up new clusters for large services such as BigTable is a long and complex process. Early automation focused on accelerating cluster delivery through scripted SSH steps to distribute packages and initialize services. Flags for fine-tuning configurations get added later on which caused wasted time in spotting misconfigurations causing out-of-memory fails. Prodtests gets introduced to allow unit testing of real-world services to verify the cluster configurations. New bugs found extends the prodtests set. With this it is possible to predict the time for a cluster to go from "network-ready" to "live-traffic-ready".
With thousands of shell scripts owned by dozens of teams, reducing the turnup time to one week becomes hard to do, as bugs found by the unit tests takes time to be fixed. Then the idea of "code fixing misconfigurations" arose. So each test is paired with a fix, and each fix is idempotent and safe to resolve; which means teams must be comfortable to run the fix-scans every 15 minute without fearing anything.
The flaws in this process are that: 1) the latency between a test -> fix -> another test sometimes introduced flaky tests; 2) not all tests are idempotent and a flaky test with fix may render the system in an inconsistent state; 3) test code dies when they are not in sync with the codebase that it covers
Due to some security requirement, the Admin Server becomes a mandate of service teams' workflows. SREs moved from writing shell scripts in their home directories to building peer-reviewed RPC servers with fine-grained ACLs.
It becomes clear that the turnup processes had to be owned by the teams that owned the services. A Service-Oriented Architecture is built around the Admin Server: Admin Server to handle cluster turnup/turndown RPCs, while each team would provide the contract (API) that the turnup automation needed, while still being free to change the underlying implementation.
Release Engineering¶
Release engineering can be concisely described as building and delivering software. It touches on source code management, compilers, build configuration languages, automated build tools, package managers, and installers. It requires skills from domains: development, configuration management, test integration, system administration, and customer support.
At Google. Release engineers work with software engineers (SWEs) in product development and SREs to define all the steps required to release software—from how the software is stored in the source code repository, to build rules for compilation, to how testing, packaging, and deployment are conducted.
Release engineers define best practices for using internal tools in order to make sure projects are released using consistent and repeatable methodologies.
Teams should budget for release engineering resources at the beginning of the product development cycle. It’s cheaper to put good practices and process in place early, rather than have to retrofit your system later. It is essential that the developers, SREs, and release engineers work together.
Philosophy¶
Release engineering is guided by four major principles:
- Self-Service Model
- teams must be self-sufficient to achieve high release velocity
- release processes can be automated
- invole engineer only when problems arise
- High Velocity
- frequent releases with fewer changes between versions
- better testing and troubleshooting, less changes to look through between releases
- can accumulate builds then pick a version to deploy, or simply "push on green"
- Hermetic Builds
- build tools must ensure consistency and repeatability
- build process is self-contained and does not rely on external services outside the build environment
- Enforcement of Policies and Procedures
- gate operations ensure security and access control
- approve merging code changes
- release process actions selection
- creating a new release
- reploying a new release
- updates build configuration
- report what has changed in a release
- speeds up troubleshooting
- gate operations ensure security and access control
CI, CD¶
Goolge's software lifecycle:
- Building binaries, define build targets
- also saves build date, revision number, and build id for record-keeping
- Branching
- all code branches off from the main source code tree
- major projects branch from mainline at a specific revision and never merge from mainline again
- bug fixes in mainline are cherry-picked into the project branch for inclusion in releases
- Testing
- mainline runs unit tests at each submitted change
- create releases at the revision number of last continuous test build that completed all tests
- release re-run the unit tests and create an audit trail for all tests passed
- Packaging
- software is distributed via Midas Package Manager (MPM)
- packaged files along with owners and permissions, named, versioned with unique hash, labeled, and signed for authenticity
- labels are used to indicate the environment intended for that package, i.e. dev, canary, or production
- Rapid
- the CI/CD platform. Blueprints configures and defines the build and test targets, rule for deployment, and admin information
- role-based access control determine who can perform actions on a project
- compilation and testing occur in parallel and each in their dedicated environments
- artifacts then gets through system testing and canary deployments
- each step results are logged, a report is created for what changed since last release
- Deployment
- for more compicated deployments, Sisyphus kicks in as a general-purpose rollout automation framework
- Rapid creates a rollout in a long-running Sisyphus job, and pass on the MPM package with the versioned build label
- rollout can be simple fan out or progressive depending on the service's risk profile
Configuration Management¶
Although sounds simple, configuration changes are a potential source of instability.
Configuration management at Google requires storing configuration in the source code repository and enforcing a strict code review. Here are some strategies:
- update configuration at the mainline
- decouples binary releases from configuration changes
- may lead to skew between checked-in version and running version of configuration files
- pack configuration files with binary files
- built into MPM package
- simplifies deployment, limits flexibility
- pack configuration files as configuration MPMs
- dedicated MPM package for configuration files
- can pair with a binary MPM, both package can be built independently then deployed together within the same release
- read configuration from an external store
- good for projects that need frequent or dynamically updated configurations
Simplicity¶
Changes have a side effect of introducing bugs and instability to the system.
A good summary of the SRE approach to managing systems is: "At the end of the day, our job is to keep agility and stability in balance in the system." SREs work to create procedures, practices, and tools that render software more reliable. At the same time, SREs ensure that this work has as little impact on developer agility as possible.
Reliable processes tend to actually increase developer agility: rapid, reliable production rollouts make changes in production easier to see. Once a bug surfaces, it takes less time to find and fix that bug.
"Boring" virtue¶
"Borning" is a desireable property when it comes to software source code. The lack of excitement, suspense, and puzzles, and minimizing accidental complexity helps predictably accomplish the software's business goals.
Remove bloat¶
When code are bound to delete, delete them, never do commenting them out, or put a flag and hope they can be used at some point later. SRE should promote practices that ensure existing code all serve the essential purpose, routinely removing dead code, and building bloat detection into all levels of testing.
Software bloat are the tendency of software to become slower and bigger over time as a result of constant additional features. A smaller project is easier to understand, easier to test, and frequently has fewer defects.
Minimal, Modularity, Simple Release¶
The ability to make changes to parts of the system in isolation is essential to creating a supportable system. Loose coupling between binaries, or between binaries and configuration, is a simplicity pattern that simultaneously promotes developer agility and system stability.
Versioning APIs allows developers to continue to use the version that their system depends upon while they upgrade to a newer version in a safe and considered way. One of the central strengths and design goals of Google’s protocol buffers was to create a wire format that was backward and forward compatible.
Writing clear, minimal APIs is an essential aspect of managing simplicity in a software system.
Prefer simple releases. It is much easier to measure and understand the impact of a single change rather than a batch of changes released simultaneously.
Best Practices¶
Successfully operating a service entails a wide range of activities: developing monitoring systems, planning capacity, responding to incidents, ensuring the root causes of outages are addressed, and so on.
A healthy way to operate a service permits self-actualization and takes active control of the direction of the service rather than reactively fights fires.
Service Reliability Hierarchy: the elements that go into making a service reliable:
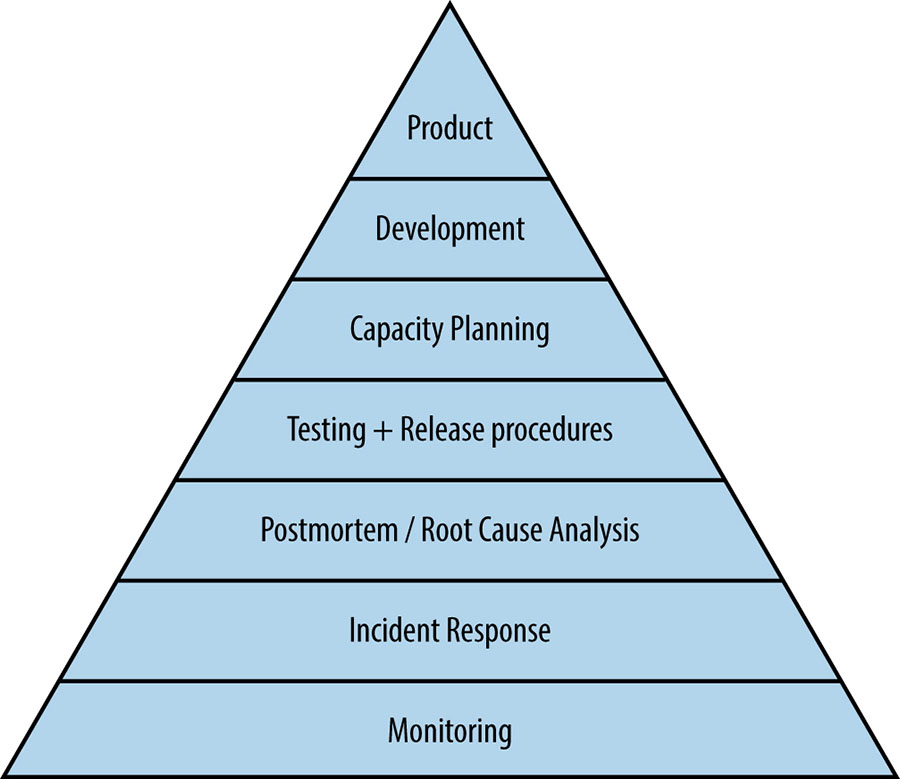
- Monitoring - you want to be aware of problems before your users notice them
- Incident Response - it is a tool we use to achieve our larger mission and remain in touch with how distributed computing systems actually work and fail
- Postmortem and RCA - building a blameless postmortem culture is the first step in understanding what went wrong and prevent same issue gets popped up
- Testing - offer some assurance that our software isn’t making certain classes of errors before it’s released
- Capacity Planning - how requests are load-balanced and potential overload handled, prevent cascading failures
- Development - large-scale system design and implementation
- Product - reliable product launched at scale
Practical Alerting¶
Monitoring is the fundamental element to running a stable service. Monitoring a large system is challenging:
- the sheer number of components to analyze
- maintain low maintenance burden on engineers responsible for the system
The Borgmon story¶
Borgmon is the monitoring system for the job scheduling infrasture.
It relies on a common data exposition format which allowed mass data collection with low overheads and avoids the costs of subprocess execution and network connection setup. The data is used both for rendering charts and creating alerts. The history of the collected data can be used for alert computation as well.
A Borgmon can collect from other Borgmon, so it can build hierarchies that follow the topology of the service, aggregating and summarizing information and discarding some strategically at each level. Some very large services shard below the cluster level into many scraper Borgmon, which in turn feed to the cluster-level Borgmon.
App instrumentation¶
Borgmon used a format to export metrics in plain text as space-separated keys and values, one metric per line.
Adding a metric to a program only requires a single declaration in the code where the metric is needed.
The decoupling of the variable definition from its use in Borgmon rules requires careful change management, and this trade-off has been offset with proper tools to validate and generate monitoring rules.
Borgmon uses service discover to figure out the targets to scrape metric data from. The target list is dynamic whic hallows the monitoring to scale automatically.
Additional "synthetic" metrics variables for each target helps detect if the monitored tasks are unavailable.
Time-series data storage¶
Borgmon stores all the data in an in-memory database, regularly checkpointed to disk. Data points are of form (timestamp, value), and stored in chronological lists aka time-series. Each time-series is named by a unique set of labels of form name=value.
A time-series is conceptually a one-dimensional matrix of numbers, progressing through time. As you add permutations of labels to this time-series, the matrix becomes multidimensional.
In practice, the structure is a fixed-sized block of memory, known as the time-series arena, with a garbage collector that expires the oldest entries once the arena is full. The time interval between the most recent and oldest entries in the arena is the horizon, which indicates how much queryable data is kept in RAM.
Periodically, the in-memory state is archived to an external system known as the Time-Series Database (TSDB). Borgmon can query TSDB for older data and, while slower, TSDB is cheaper and larger than a Borgmon’s RAM.
Time-series are stored as sequences of numbers and timestamps, which are referred to as vectors. The name of a time-series is a labelset.
To make a time-series identifiable, it must have labels:
- var - name of the variable/metric
- job - type of server being monitored
- service - collection of jobs that provide a service to users
- zone - datacenter location/region
Together these label variables appear like this {var=http_requests,job=webserver,instance=host0:80,service=web,zone=us-west}[10m] called variable expression. A search for a labelset returns all matching time-series in a vector and does not require all labels to be specified. A duration can be specified to limit the range of data to query from.
Rules¶
Borgmon rules consists of simple algebraic expressions that compute time-series from other time-series. Rules run in a parallel threadpool where possible.
Borgmon rules create new time-series, so the results of the computations are kept in the time-series arena and can be inspected just as the source time-series are. The ability to do so allows for ad hoc querying, evaluation, and exploration as tables or charts.
Aggregation is the cornerstone of rule evaluation in a distributed environment. A counter is any monotonically non-decreasing variable. Gauges may take any value they like.
Alerting¶
When an alerting rule is evaluated by a Borgmon, the result is either true, in which case the alert is triggered, or false. Alerts sometimes toggle their state quickly, thus the rules allow a minimum duration (at least two rule evalutation cycles) for which the alerting rule must be true before the alert is sent.
The alert rule allows templating for filling out a message template with contextual information when the alert fires and sent to alerting RPC.
Alerts get first sent as "triggering" and then as "firing". The Alertmanager is responsible for routing the alert notification to the correct destination, and alerts will be dedupted, snoozed, or fan out/in base on the labelsets.
Sharding Monitoring¶
A Borgmon can import time-series data from other Borgmon. To avoid scaling bottlenecks, a streaming protocol is used to transmit time-series data between Borgmon. Such deployment uses two or more global Borgmon for top-level aggregation and one Borgmon in each datacenter to monitor all the jobs running at that location.
Upper-tier Borgmon can filter the data they want to stream from the lower-tier Borgmon, so that the global Borgmon does not fill its arena with all the per-task time-series from the lower tiers. Thus, the aggregation hierarchy builds local caches of relevant time-series that can be drilled down into when required.

Black-box monitoring¶
Borgmon is a white-box monitoring system—it inspects the internal state of the target service, and the rules are written with knowledge of the internals in mind.
Prober is used to run a protocol check against a target and reports success or failure. Prober can also validate the response payload of the protocol to verify that the contents are expected, and even extract and export values as time-series. The prober can send alerts directly to Alertmanager, or its own varz can be collected by a Borgmon.
Teams often use Prober to export histograms of response times by operation type and payload size so that they can slice and dice the user-visible performance. Prober is a hybrid of the check-and-test model with some richer variable extraction to create time-series.
Prober can be pointed at either the frontend domain or behind the load balancer to know that traffic is still served when a datacenter fails, or to quickly isolate an edge in the traffic flow graph where a failure has occurred.
Configuration¶
Borgmon configuration separates the definition of the rules from the targets being monitored. The same sets of rules can be applied to many targets at once, instead of writing nearly identical configuration over and over.
Borgmon also supports language templates to reduce repetition and promote rules reuse.
Borgmon adds labels indicating the target’s breakdown (data type), instance name (source of data), and the shard and datacenter (locality or aggregation) it occupies, which can be used to group and aggregate those time-series together.
The templated nature of these libraries allows flexibility in their use. The same template can be used to aggregate from each tier.
Borgmon of Ten Years¶
Borgmon transposed the model of check-and-alert per target into mass variable collection and a centralized rule evaluation across the time-series for alerting and diagnostics. This decoupling allows the size of the system being monitored to scale independently of the size of alerting rules.
New applications come ready with metric exports in all components and libraries to which they link, and well-traveled aggregation and console templates, which further reduces the burden of implementation.
Ensuring that the cost of maintenance scales sublinearly with the size of the service is key to making monitoring (and all sustaining operations work) maintainable. This theme recurs in all SRE work, as SREs work to scale all aspects of their work to the global scale.
The idea of treating time-series data as a data source for generating alerts is now accessible to everyone through those open source tools like Prometheus, Riemann, Heka, and Bosun.
On-Calls¶
Historically, On-calls in IT context are performed by dedicated Ops teams tasked with the primary responsibility of keeping the service(s) for which they are responsible in good health.
The SRE teams are quite different from purely operational teams in that they place heavy emphasis on the use of engineering to approach problems that exist at a scale and would be intractable without software engineering solutions.
Duty¶
When on-call, an engineer is available to triage the problem and perform operations on production systems possibly involving other team members and escalating as needed, within minutes. Typical values are 5 minutes for user-facing or otherwise highly time-critical services, and 30 minutes for less time-sensitive systems, depending on a service's SLO.
Nonpaging production events, such as lower priority alerts or software releases, can also be handled and/or vetted by the on-call engineer during business hours.
Many teams have both a primary and a secondary on-call rotation to serve as a fall-through for the pages. It is also common for two related teams to serve as secondary on-call for each other, with fall-through handling duties, rather than keeping a dedicated secondary rotation.
Balance¶
The quantity of on-call can be calculated by the percent of time spent by engineers on on-call duties. The quality of on-call can be calculated by the number of incidents that occur during an on-call shift.
Google strive to invest at least 50% of SRE time into engineering: of the remainder, no more than 25% can be spent on-call, leaving up to another 25% on other types of operational, nonproject work.
Using the 25% rule to derive the minimum number of SREs requried to sustain a 24/7 on-call rotation. Prefer a multi-site team of on-call shifts for these reasons:
- a multi-site "follow the sun" rotation allows teams to avoid night shifts altogether
- limiting the number of engineers in the on-call rotation ensures that engineers do not lose touch with the production systems
For each on-call shift, an engineer should have sufficient time to deal with any incidents and follow-up activities such as writing postmortems.
Feeling Safe¶
It’s important that on-call SREs understand that they can rely on several resources that make the experience of being on-call less daunting than it may seem. The most important on-call resources are:
- Clear escalation paths
- Well-defined incident-management procedures
- A blameless postmortem culture
Look into adopting a formal incident-management protocol that offers an easy-to-follow and well-defined set of steps that aid an on-call engineer to rationally pursue a satisfactory incident resolution with all the required help.
Build or adopt tools that automates most of the incident management actions, so the on-call engineer can focus on dealing with the incident, rather than spending time and cognitive effort on mundane actions such as formatting emails or updating several communication channels at once.
When an incident occurs, it’s important to evaluate what went wrong, recognize what went well, and take action to prevent the same errors from recurring in the future. SRE teams must write postmortems after significant incidents and detail a full timeline of the events that occurred.
Mistakes happen, and software should make sure that we make as few mistakes as possible. Recognizing automation opportunities is one of the best ways to prevent human errors.
Avoid Overload¶
The SRE team and leadership are responsible for including concrete objectives in quarterly work planning in order to make sure that the workload returns to sustainable levels.
Misconfigured monitoring is a common cause of operational overload. Paging alerts should be aligned with the symptoms that threaten a service’s SLOs. All paging alerts should also be actionable. Low-priority alerts that bother the on-call engineer every hour (or more frequently) disrupt productivity, and the fatigue such alerts induce can also cause serious alerts to be treated with less attention than necessary.
It is also important to control the number of alerts that the on-call engineers receive for a single incident, regulate the alert fan-out by ensuring that related alerts are grouped together by the monitoring or alerting system. Noisy alerts that systematically generate more than one alert per incident should be tweaked to approach a 1:1 alert/incident ratio.
In extreme cases, SRE teams may have the option to "give back the pager"—SRE can ask the developer team to be exclusively on-call for the system until it meets the standards of the SRE team in question. It is appropriate to negotiate the reorganization of on-call responsibilities with the development team, possibly routing some or all paging alerts to the developer on-call.
Avoid Underload¶
When SREs are not on-call often enough, they start losing confidence in operations touching the production, and creating knowledge gaps.
SRE teams should be sized to allow every engineer to be on-call at least once or twice a quarter, thus ensuring that each team member is sufficiently exposed to production.
Regular trainings and exercises should also be conducted to help improve troubleshooting skills and knowledge of the services.
Effective Troubleshooting¶
Be warned that being an expert is more than understanding how a system is supposed to work. Expertise is gained by investigating why a system doesn't work.
While you can investigate a problem using only the generic process and derivation from first principles, it is less efficient and less effective than understanding how things are supposed to work.
Theory¶
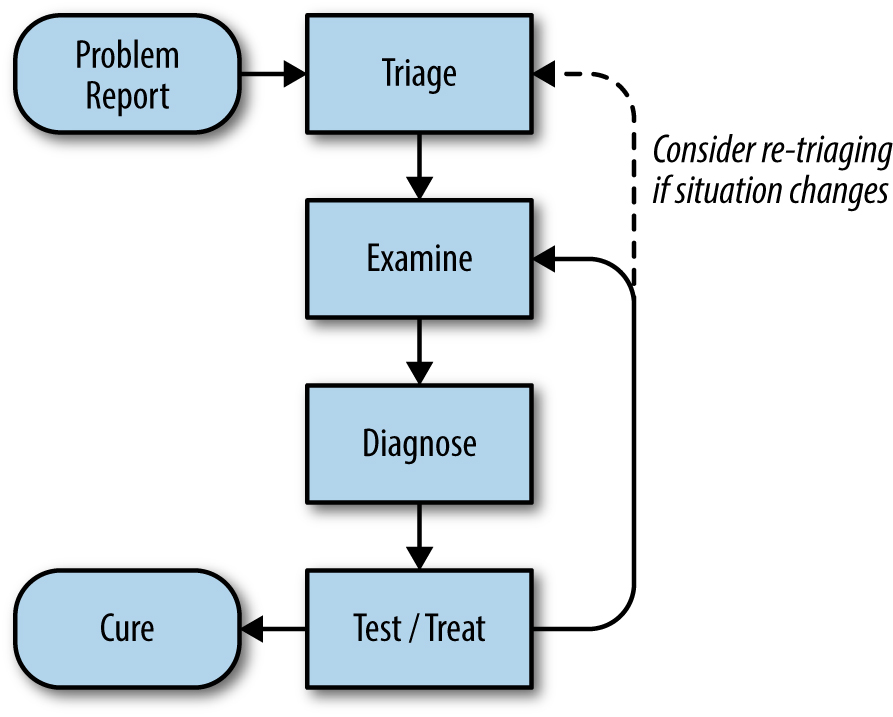
Think of the troubleshooting process as an application of the hypothetico-deductive method: given a set of observations about a system and a theoretical basis for understanding system behavior, we iteratively hypothesize potential causes for the failure and try to test those hypotheses.
We’d start with a problem report telling us that something is wrong with the system. Then we can look at the system’s telemetry and logs to understand its current state. This information, combined with our knowledge of how the system is built, how it should operate, and its failure modes, enables us to identify some possible causes.
Avoid Pitfalls¶
The following are common pitfalls to avoid:
- Looking at symptoms that aren’t relevant or misunderstanding the meaning of system metrics
- Misunderstanding how to change the system, its inputs, or its environment, so as to safely and effectively test hypotheses
- Coming up with wildly improbable theories about what’s wrong, or latching on to causes of past problems, reasoning that since it happened once, it must be happening again
- Hunting down spurious correlations that are actually coincidences or are correlated with shared causes
Understanding failures in our reasoning process is the first step to avoiding them and becoming more effective in solving problems. A methodical approach to knowing what we do know, what we don’t know, and what we need to know, makes it simpler and more straightforward to figure out what’s gone wrong and how to fix it.
In Practice¶
Problem Report¶
An effective problem report should tell you the expected behavior, the actual behavior, and, if possible, how to reproduce the behavior. Ideally, the reports should have a consistent form and be stored in a searchable location.
It’s common practice at Google to open a bug for every issue, even those received via email or instant messaging. Doing so creates a log of investigation and remediation activities that can be referenced in the future.
Discourage reporting problems directly to a person, which introduces an additional step of transcribing the report into a bug, produces lower-quality reports that aren’t visible to other members of the team, and tends to concentrate the problem-solving load on a handful of team members that the reporters happen to know, rather than the person currently on duty.
Triage¶
Problems can vary in severity: an issue might affect only one user under very specific circumstances, or it might entail a complete global outage for a service. Your response should be appropriate for the problem’s impact and your course of action should be to make the system work as well as it can under the circumstances.
For example, if a bug is leading to possibly unrecoverable data corruption, freezing the system to prevent further failure may be better than letting this behavior continue.
Examine¶
Graphing time-series and operations on time-series can be an effective way to understand the behavior of specific pieces of a system and find correlations that might suggest where problems began.
Logging and exporting information about each operation and about system state makes it possible to understand exactly what a process was doing at a given point in time.
Text logs are very helpful for reactive debugging in real time, while storing logs in a structured binary format can make it possible to build tools to conduct retrospective analysis with much more information.
It’s really useful to have multiple verbosity levels available, along with a way to increase these levels on the fly. This functionality enables you to examine any or all operations in incredible detail without having to restart your process, while still allowing you to dial back the verbosity levels when your service is operating normally.
Exposing current state is the third trick. Google servers have endpoints that show a sample of RPCs recently sent or received, to help understand how any one server is communicating with others without referencing an architecture diagram. These endpoints also show histograms of error rates and latency for each type of RPC, their current configuration or allow examination of their data.
Lastly, you may even need to instrument a client to experiment with, in order to discover what a component is returning in response to requests.
Diagnose¶
Ideally, components in a system have well-defined interfaces and perform known transformations from their input to their output. It's then possible to look at the data flows between components to determine whether a given component is working properly.
Injecting known test data in order to check that the resulting output is expected at each step can be especially effective (a form of black-box testing).
Dividing and conquering is a very useful general-purpose solution technique. An alternative, bisection, splits the system in half and examines the communication paths between components on one side and the other.
Finding out what a malfunctioning system is doing (symptom), then asking why (cause of symptom) it’s doing that and where (locate the code) its resources are being used or where its output is going can help you understand how things have gone wrong and forge a solution.
A working computer system tends to remain in motion until acted upon by an external force, such as a configuration change or a shift in the type of load served. Recent changes to a system can be a productive place to start identifying what’s going wrong.
Correlating changes in a system’s performance and behavior with other events in the system and environment can also be helpful in constructing monitoring dashboards, i.e. annotate a graph showing the system’s error rates with the start and end times of a deployment of a new version.
Test and Treat¶
Using the experimental method, we can try to rule in or rule out our hypothetic list of possible causes. Following the code and trying to imitate the code flow, step-by-step, may point to exactly what’s going wrong.
Consider these when designing tests:
- a test should have mutually exclusive alternatives, so that it can rule one group of hypotheses in and rule another set out
- obvious first: perform the tests in decreasing order of likelihood
- an experiment may provide misleading results due to confounding factors
- i.e. firewall rules against your workstation but not for the application server
- side effects that change future test results
- if you performed active testing by changing a system—for instance by giving more resources to a process—making changes in a systematic and documented fashion will help you return the system to its pre-test setup
- tests can be suggestive rather than definitive
- i.e. it can be very difficult to make race conditions or deadlocks happen in a timely and reproducible manner
Negative Results¶
Negative results should not be ignored or discounted. Realizing you’re wrong has much value: a clear negative result can resolve some of the hardest design questions. Often a team has two seemingly reasonable designs but progress in one direction has to address vague and speculative questions about whether the other direction might be better.
Experiments with negative results are conclusive. They tell us something certain about production, or the design space, or the performance limits of an existing system. They can help others determine whether their own experiments or designs are worthwhile. Microbenchmarks, documented antipatterns, and project postmortems all fit this category.
Tools and methods can outlive the experiment and inform future work. As an example, benchmarking tools and load generators can result just as easily from a disconfirming experiment as a supporting one.
Publishing negative results improves our industry’s data-driven culture. Accounting for negative results and statistical insignificance reduces the bias in our metrics and provides an example to others of how to maturely accept uncertainty.
Cure¶
Often, we can only find probable root cause factors than definitive factor, given that a production system can be complex and reproducing the problem in a live production system may not be an option.
Once you’ve found the factors that caused the problem, it’s time to write up notes on what went wrong with the system, how you tracked down the problem, how you fixed the problem, and how to prevent it from happening again (a postmortem).
Emergency Response¶
What to Do When Systems Break? Don't panic. If you can’t think of a solution, cast your net farther. Involve more of your teammates, seek help, do whatever you have to do, but do it quickly. The highest priority is to resolve the issue at hand quickly. Oftentimes, the person with the most state is the one whose actions somehow triggered the event. Utilize that person.
Keep a History of Outages. History is about learning from everyone’s mistakes. Be thorough, be honest, but most of all, ask hard questions. Look for specific actions that might prevent such an outage from recurring, not just tactically, but also strategically.
Hold yourself and others accountable to following up on the specific actions detailed in these postmortems. Doing so will prevent a future outage that’s nearly identical to, and caused by nearly the same triggers as, an outage that has already been documented.